
Анализ эффективности параллельных вычислений в среде SIMULIA Abaqus на вычислительной платформе Aurora G-Station
Введение
Всё большее количество компаний используют инструменты математического моделирования для улучшения функциональных характеристик своей продукции и сокращения временных и финансовых затрат на ее разработку. Современные расчетные модели отличаются высокой степенью детализации и большими возможностями по учету различных факторов. Однако высокая степень детализации и усложнение постановок математических моделей требуют проведения огромного числа трудоемких вычислений и, как следствие, возникает необходимость использования высокопроизводительных программноаппаратных вычислительных комплексов. Такого рода инженерные задачи относятся к области высокопроизводительных вычислений (HighPerformance Computing).
Выбор программноаппаратного комплекса сегодня — это поиск компромиссного решения между такими факторами, как пиковая производительность для выбранного набора прикладного программного обеспечения, совокупная стоимость комплекса и его долгосрочной эксплуатации, минимизация капитальных и операционных расходов и, конечно, удобство использования для конечных пользователей. На сегодняшний день лицензионная политика большинства коммерческих конечноэлементных пакетов предполагает увеличение общей стоимости лицензии с увеличением количества процессорных элементов, задействованных в расчете. Тем не менее на практике многие прикладные инженерные пакеты эффективно масштабируются лишь до определенного количества процессорных элементов, прчем дальнейшее увеличение числа процессорных элементов не приводит к сокращению времени выполнения задачи. Таким образом, можно сказать, что оптимальный выбор программной и аппаратной составляющих вычислительной системы для инженерных расчетов сегодня — это, прежде всего, баланс цены и производительности, в метрике общего числа типовых задач, которые могут быть просчитаны за сутки. Оптимизация расходов на создание вычислительной системы при должном уровне эффективности является весьма актуальной задачей, особенно в рамках текущей экономической ситуации.
В настоящей работе представлены результаты тестирования производительности явного решателя конечноэлементного комплекса SIMULIA Abaqus на вычислительной платформе Eurotech Aurora GStation. На основе полученных данных сформулированы общие рекомендации по выбору оптимальной, в плане соотношения «цена/производительность», лицензии SIMULIA Abaqus и конфигурации аппаратной части.
Программная и аппаратная части
SIMULIA Abaqus является программным комплексом мирового уровня в области конечноэлементного анализа. Существенным преимуществом SIMULIA Abaqus является реализация двух решателей в рамках одного продукта: Abaqus/Explicit и Abaqus/Standard, основанных на явной и неявной схемах интегрирования соответственно. Это позволяет проводить решение различных типов инженерных задач (статики, динамики, термопрочности) в режиме использования одного программного пакета без необходимости экспорта моделей в сторонние продукты. Тестирование производительности было выполнено для каждого из решателей. Тем не менее в данной статье представлены материалы только для решателя Abaqus/Explicit, а результаты тестирования Abaqus/Standard и вычислений на графических картах (GPU), ввиду избыточного количества материала, будут выделены в отдельную статью. Тестирование осуществлялось на версии Abaqus 6.143.
Решатель Abaqus/Explicit использует явную схему интегрирования уравнений движения по времени. На каждой итерации проводится решение уравнений динамического равновесия с диагональной матрицей масс элементов. Метод является условно устойчивым; предел устойчивости ограничен размером временного приращения, которое равно времени прохождения волны через конечный элемент. В основном решатель Abaqus/Explicit используется для моделирования быстротекущих динамических процессов, однако с применением соответствующих техник моделирования возможно решение существеннонелинейных квазистатических задач. Помимо этого на базе решателя Abaqus/Explicit реализован целый ряд относительно новых методов численного анализа, таких как связанный метод Эйлера — Лагранжа (CEL), гидродинамика сглаженных частиц (SPH), метод дискретных элементов (DEM).
Для проведения теста производительности был выбран ряд типовых задач, которые представляют наиболее распространенные приложения Abaqus/Explicit:
- тест E1: краштест автомобиля;
- тест E2: листовая штамповка;
- Тест E3: задача пробития;
- Тест E4: соударение с птицей (Bird strike).

Рис. 1. Тестовые задачи: а — E1: краш-тест автомобиля; б — E2: листовая штамповка;
в — E3: задача пробития; г — E4: соударение с птицей (Bird strike)
На рис. 1 приведены изображения финальных конфигураций каждой из тестовых моделей. В тесте E1 проводится моделирование фронтального краштеста легкового автомобиля. Конечноэлементная модель в основном состоит из оболочечных элементов типа S3RS и S4RS. Поведение материалов описывается упругопластическими моделями с изотропным упрочнением и полиномиальными гиперупругими моделями. Различные компоненты автомобиля соединены с помощью многоточечных закреплений и коннекторов. Некоторые элементы подвески и трансмиссии представлены в виде абсолютно жестких тел. Для описания контактных взаимодействий между автомобилем, дорогой и абсолютно жесткой преградой используется алгоритм общего контакта (General Contact). Следующий тест — E2 посвящен моделированию листовой штамповки. Для получения квазистатического решения и минимизации инерционной составляющей процесса используется технология масштабирования массы (Mass scaling), которая позволяет управлять размером явного шага по времени. Анализ состоит из двух этапов. На первом шаге заготовка зажимается между оправкой и штампом. На втором шаге штамп перемещается и деформирует деталь. Заготовка аппроксимируется оболочечными конечными элементами S4R, а жесткая модель штампа — поверхностными элементами типа SFM3D4R. Взаимодействие заготовки с поверхностью штампов описывается с помощью механизма контактных пар (Contact pairs). В тесте E3 рассматривается задача пробития пулей стальной плиты. Математические модели пули и преграды созданы на базе объемных конечных элементов C3D8R. Для описания поведения материала используется одна из моделей нелинейной механики разрушений — модель Бао — Вербицки. Активирован критерий удаления элементов по мере исчерпания своей несущей способности. Контактные взаимодействия описываются алгоритмом General Contact, позволяющим учитывать контактные ограничения между новыми поверхностями, образующимися в процессе разрушения материала. В последней тестовой задаче — E4 (Bird strike) проводится имитация процесса соударения летящей птицы с цилиндрической поверхностью. Задача решается с использованием связанного метода Эйлера — Лагранжа (CEL). Модель птицы представлена в Эйлеровой постановке, цилиндрические поверхности — в Лагранжевой. Определена возможность разрушения Лагранжевых поверхностей.

Рис. 2. G-Station шасси и вид одного вычислительного узла. Размеры вычислительного блока (ВЅШЅГ) — 70x65x80 cм
Тестирование пакета SIMULIA Abaqus проводилось на предоставленном компанией ПРОСОФТ суперкомпьютере с непосредственным водяным охлаждением — Eurotech Aurora GStation (рис. 2). Задействованная в работе станция была укомплектована четырьмя вычислительными узлами, каждый из которых содержал два процессора Intel Xeon E52650 v2, два GPGPUвидеоускорителя NVIDIA K20s, 64 Гбайт DDR3 доступной оперативной памяти и твердотельный накопитель емкостью 240 Гбайт. При этом оперативная память была организована в две NUMAноды, по 32 Гбайт каждая. Все вычислительные узлы объединены высокоскоростной коммутационной сетью Mellanox QDR ConnectX2 InfiniBand (IB), а также стандартной сетью 1G Ethernet. Пропускная способность сети IB составляет 3,1 Гбит/с, тогда как соответствующий параметр для сети 1G Ethernet — всего лишь 120 Мбит/с.
Кэш данных и инструкций в Intel Xeon E52650 v2 организован следующим образом: один общий на процессор кэш третьего уровня (L3) объемом 20 Мбайт, и независимые кэши первого и второго (L1/L2) уровней на каждом из ЦПУядер. Cуммарное вычислительное поле было представлено восемью процессорами с 64 ЦПУядрами архитектуры Intel Ivy Bridge с тактовой частотой 2,6 Гц каждое. Согласно результатам теста производительности HighPerformance Linpack (HPL), пиковая (теоретическая) ЦПУпроизводительность данной конфигурации составила 1,2 (1,3) Терафлопс. В процессе тестирования GStation работала под управлением операционной системы Linux Cent OS версии 6.4.
Расчеты проводились с системными настройками по умолчанию, а именно:
- HyperThreading (HT) был отключен, то есть число логических ЦПУ было равно числу физических ЦПУядер, за исключением тех тестов, где проводилось исследование влияния технологии HT на общую производительность решателя;
- технология динамического изменения тактовой частоты ЦПУядер Intel Turbo Boost была активирована. С активированным Intel Turbo Boost, в состоянии простоя, тактовая частота всех ЦПУядер Intel Xeon E52650 v2 — 1,2 Гц, тогда как максимально возможная тактовая частота отдельных ЦПУядер может достигать пикового значения в 3,4 Гц;
- вся выделяемая приложением оперативная память равномерно распределялась между двумя NUMAнодами — так называемый interleaveалгоритм;
- в рамках одного вычислительного узла параллельные процессы, создаваемые решателем Abaqus/Explicit, распределялись циклически между двумя процессорами — так называемый roundrobin алгоритм (MPI_CPU_AFFINITY=CYCLIC для Platform MPI v9.1.2).
Результаты тестирования
В рамках одного вычислительного узла
Обсуждение полученных результатов целесообразно начать с данных масштабирования тестов E1Е4 в рамках одного вычислительного узла. Как хорошо видно из данных по масштабированию явного решателя Abaqus/Explicit, представленных на рис. 3, переход от последовательного режима выполнения на одном ЦПУядре в параллельный режим на двух ЦПУядрах приводит к суперлинейному ускорению явного решателя. Действительно, согласно закону Амдала, идеальный теоретический коэффициент ускорения для двух процессов должен быть равен 2, тогда как в нашем случае этот коэффициент варьируется от 2,0 до 2,6 раз: E2 — до 2, E1 и E4 — до 2,4, E3 — до 2,6. Такое суперлинейное ускорение возможно только на многопроцессорной аппаратной платформе и достигается, главным образом, за счет увеличения объема доступного L3кэша. Действительно, в рамках используемой двухпроцессорной конфигурации и roundrobin алгоритма распределения рабочих процессов, каждый работающий процесс эксклюзивно осуществляет вычисления на одном из двух физических ЦПУ, что приводит к эффективному удвоению L3кэша с 20 до 40 Мбайт.
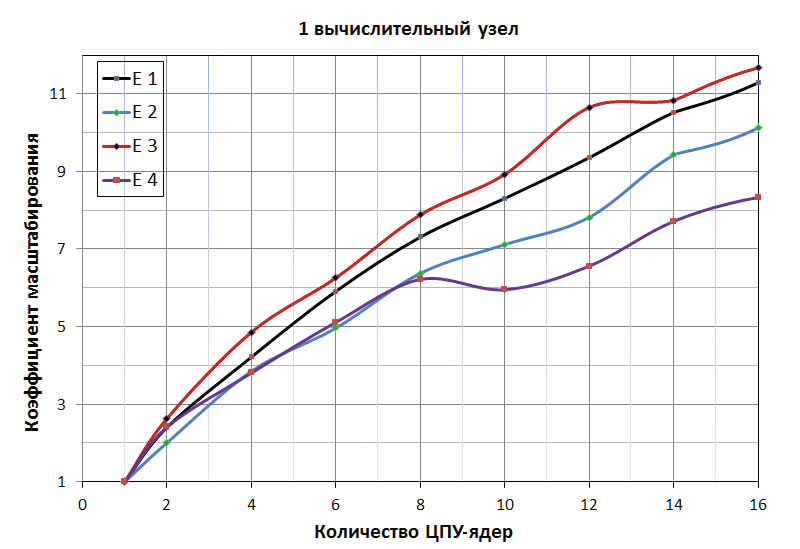
Рис. 3. Ускорение решателя Abaqus/Explicit
на одном вычислительном узле
Дальнейшее увеличение числа процессов с двух до четырех и более влечет за собой конкурентное использование L3кэшей, что, в свою очередь, ограничивает масштабируемость и эффективность вычислений. Конкурентный доступ к общему ресурсу всегда является точкой сериализации любых параллельных вычислений. К примеру, при использовании четырех ЦПУядер прирост производительности для двух тестов E1 и E3 еще сверхлинеен, но уже на шести ЦПУядрах только один тест E3 демонстрирует сверхлинейное масштабирование, тогда как другие тесты демонстрируют ускорение ниже теоретического расчетного фактора в 6 раз.
Начиная с восьми ЦПУядер прирост производительности при использовании большего числа ядер падает, что связано с всё более возрастающим уровнем конкурентного доступа к L3кэшу между возрастающим числом работающих процессов — так называемый эффект cache pressure. Как следствие этого, при использовании 16 ЦПУядер явный решатель демонстрирует лишь умеренный прирост производительности в интервале 8,311,7 раз.
Эффект от технологии HyperThreading (HT)
Современные процессоры компании Intel позволяют одновременно запускать (исполнять) два потока инструкций на одном физическом ядре. При этом оба потока уже совместно используют не только кэш третьего уровня (L3), но и кэши первого (L1) и второго (L2) уровней. Ранее, на примере L3кэша уже было показано, что параллельный и конкурентный доступ к кэшу приводит к снижению эффективности параллелизмами Abaqus/Explicit. Так как в случае HT происходит конкурентный доступ к L1/L2кэшам, то теоретический эффект от технологии HT должен быть незначительным или даже нулевым.
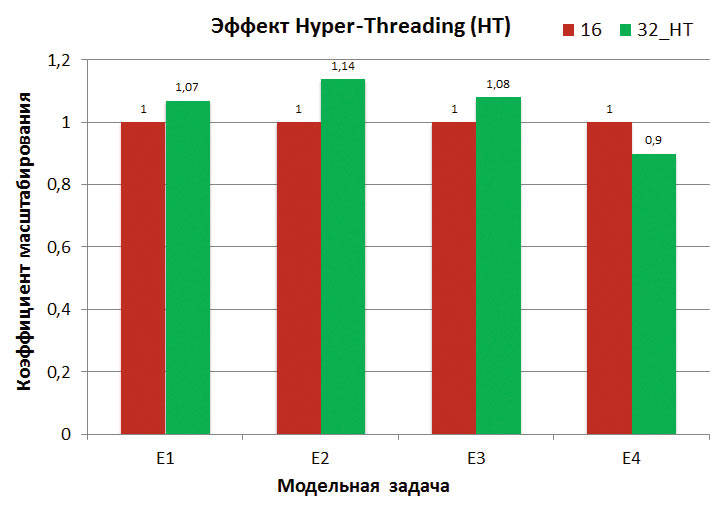
Рис. 4. Влияние Hyper-Threading на производительность решателя Abaqus/Explicit
На рис. 4 представлены данные о приросте производительности явного решателя Abaqus/Explicit, достигнутом за счет использования технологии HT. В данном случае эффект HT заключался в том, что на одном вычислительном узле стало возможным запустить 32 процесса Abaqus/Explicit вместо штатных 16.
Для модельных задач E1, E2, E3 режим HT повышает скорость работы явного решателя на 7, 14 и 8% соответственно. В то же время, в тесте E4 наблюдается 10процентное замедление в работе решателя.
Результаты на нескольких вычислительных узлах
Суммарный вычислительный эффект от проведения параллельных вычислений на нескольких узлах, как правило, определяется латентностью и пропускной способностью межузловой коммутационной сети. Используемая в тестировании вычислительная платформа Aurora GStation укомплектована высокоскоростной коммутационной сетью IB QDR 40 Гбит/с. Данная сеть характеризуется низкой (микросекундной) латентностью и высокой пропускной способностью точкаточка (3,2 Гбит/c).
Получены данные по величине ускорения решателя Abaqus/Explicit при использовании от одного до четырех вычислительных узлов (рис. 5). Каждый вычислительный узел укомплектован 16 ЦПУядрами. Коэффициент масштабирования рассчитан относительно временных данных, полученных для одного вычислительного узла.
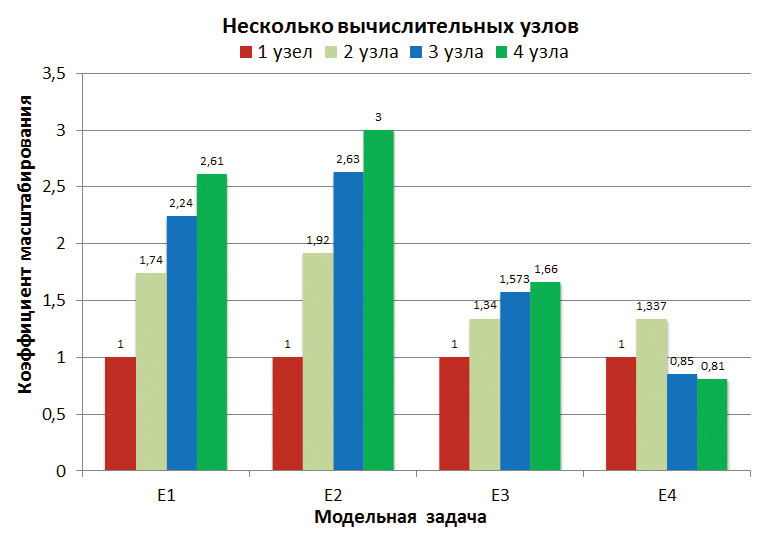
Рис. 5. Вычислительный эффект параллельных вычислений на нескольких узлах
Как видно из представленных данных, по мере увеличения количества вычислительных узлов все более четкой становится разница в масштабировании различных тестов. В тестах E1 и E2 наблюдается существенный рост производительности в 2,6 и 3 раза соответственно. Для теста E3 характерно умеренное масштабирование (до 1,6 раза). Тест E4 при запуске расчета на трех и четырех вычислительных узлах показал отрицательный результат по коэффициенту масштабирования, что может быть следствием небольшого количества активных узлов (CELпостановка) в пересчете на одно ядро.
На основе имеющихся данных масштабирования можно оценить долю последовательных (не параллельных) вычислений α на основе закона Амдала. Оценки получены двумя способами: α64, по одной точке — по результатам масштабирования, полученным на четырех вычислительных узлах (64 ЦПУядра); αмнк, методом наименьших квадратов по четырем точкам — 14 вычислительных узла (1664 ЦПУядер).
Учитывая, что доля параллельных вычислений решателя Abaqus/Explicit составляет по меньшей мере 96%, то можно теоретически оценить количество вычислительных узлов, необходимых для дальнейшего ускорения расчетов: для тестов E1 и E2 понадобится 13 вычислительных узлов (196 ЦПУядер), чтобы ускорить расчеты в 40 раз; для ускорения теста E2 в 25 раз потребуется 11 вычислительных узлов (176 ЦПУядер).
Влияние коммутационной сети на производительность
Доля последовательных вычислений явного решателя
Тест |
α64 |
αмнк |
E1 |
0,0186 |
0,0191 |
E2 |
0,0176 |
0,0181 |
E3 |
0,0360 |
0,0344 |
Предыдущая серия тестов была проведена с использованием высокоскоростной коммутационной сети IB QDR. Для изучения влияния пропускной способности и латентности коммутационной сети на производительность Abaqus/Explicit в параллельном режиме авторами осуществлены вычисления на двух вычислительных узлах, по 16 процессов (ЦПУядер) на каждом, объединенных 1G Ethernet.
Результаты тестирования приведены на рис. 6. Коэффициент масштабирования рассчитан относительно временных данных, полученных для 1G Ethernet. Для всех модельных задач использование коммутационной сети IB QDR с более высокой, по сравнению с 1G Ethernet, пропускной способностью приводит к ускорению расчетов на 1427%.
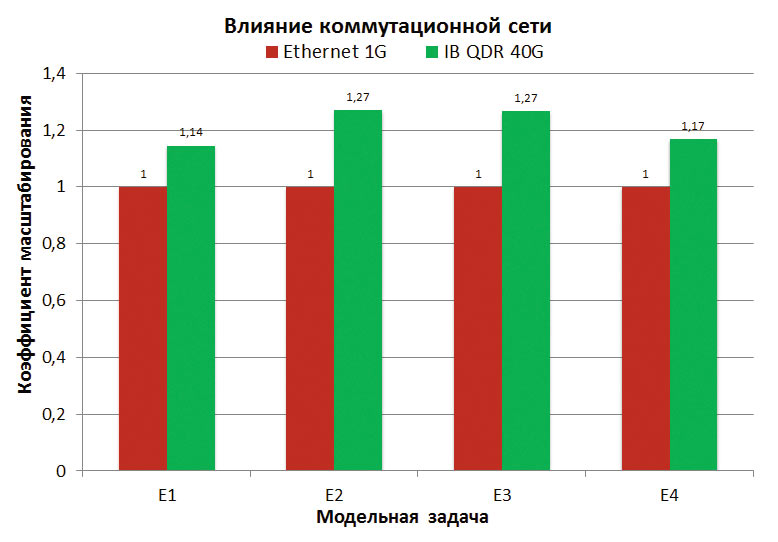
Рис. 6. Влияние коммутационной сети на производительность Abaqus/Explicit
Рекомендации
Выбор конфигурации лицензии программного комплекса SIMULIA Abaqus и аппаратной части следует осуществлять с привязкой к размерности предполагаемых задач. Для рассмотренных в ходе тестирования модельных задач (до 500 тыс. узлов) нет необходимости использовать массивнопараллельные платформы для вычислений.
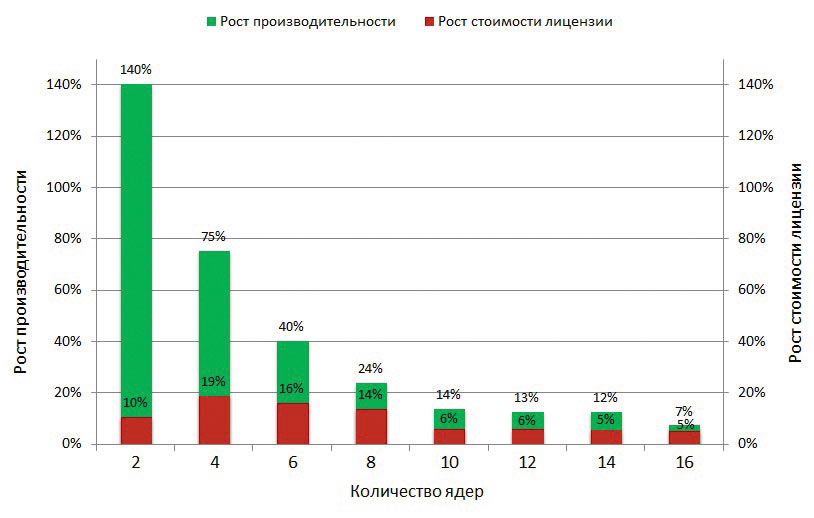
Рис. 7. Сравнение роста производительности
и увеличения стоимости лицензии
На рис. 7 представлены сравнительные диаграммы роста стоимости и производительности лицензии SIMULIA Abaqus в зависимости от количества задействованных в расчете ядер. Диаграммы приведены относительно предыдущей конфигурации. Например, по сравнению с одноядерной лицензией, двухъядерная обеспечивает рост производительности на 140%, а увеличение стоимости составляет всего 10%. Следует отметить, что во всем диапазоне рост стоимости лицензии существенно ниже роста ее производительности. Основываясь на полученных данных об области сверхлинейного ускорения и учитывая специфику лицензирования программного комплекса SIMULIA Abaqus, для задач схожей размерности авторы рекомендуют использование восьмиядерной лицензии. Данная конфигурация позволяет проводить либо решение одной задачи на восьми ядрах, либо одновременный запуск двух задач на двух ядрах каждая. К примеру, для такого рода задач можно использовать рабочую станцию, оснащенную одним процессором Intel Core i75960X и 64 Гбайт оперативной памяти.
В целях оптимального применения функционала лицензии и учитывая результаты тестирования технологии HyperThreading, авторы не рекомендуют использование данного режима на многосокетных многоядерных аппаратных конфигурациях/платформах, так как он не обеспечивает соразмерного роста производительности по отношению к росту физических ядер.
Для эффективного решения задач большей размерности (более 500 тыс. узлов) либо решения оптимизационных задач целесообразно применение вычислительной мощности нескольких узлов. В этом случае для Abaqus/Explicit оптимальной конфигурацией представляются дватри двухсокетных вычислительных узла, напрямую соединенных по InfiniBand. Важно подчеркнуть, что стоимость одного IBхостадаптера составляет всего 1015% от стоимости одного серверного ЦП

