

Александр Попов, технический директор SIGNAL

Петр Манин,
к.т.н., эксперт в цифровом строительстве
Отступления
Представленная в статье методология применима к программному обеспечению (ПО) различных разработчиков, в том числе к продуктам, взаимодействующим через формат IFC в рамках OpenBIM. Для используемой терминологии авторы выбирают названия сущностей одного из ПО, однако могут применяться и их эквиваленты. Например, Категория, Семейство и Типоразмер могут в других пакетах иметь названия Слой, Компонент, Стиль и т.п.
Аналогично, иллюстрации приводятся из программного продукта SIGNAL, однако авторы оставляют возможность реализации данного функционала в другом аналогичном ПО и будут рады любой обратной связи с такими примерами.
Исходные данные
Проектная организация разрабатывает полноценный BIMпроект. Требования к информационной модели (далее — ИМ), которую она готовит, включают требования к ее составу и содержанию (элементы и атрибуты для этих элементов, необходимые к моделированию для данной конкретной стадии, например, в рамках BEP). В проектной организации есть BIMспециалист (например, BIMкоординатор), который умеет с помощью определенного инструмента проверять ИМ на коллизии, полноту параметров и их дублирование. В этой организации разработан корпоративный классификатор элементов, который помогает описать однозначное обращение к каждому элементу, например, в рамках поиска или выборки. Стандартной разбивки на категории/стили при этом в современных САПР недостаточно: иногда при использовании сортировки по категории отображается совершенно другой строительный элемент изза особенностей ПО или непреднамеренной ошибки проектировщика.
Итак, организация разработала ИМ, ее элементы заполнены необходимой атрибутивной информацией и кодом по классификатору, из данной модели оформлены чертежи и спецификации (что часто бывает далеко не очевидным) — рис. 1.
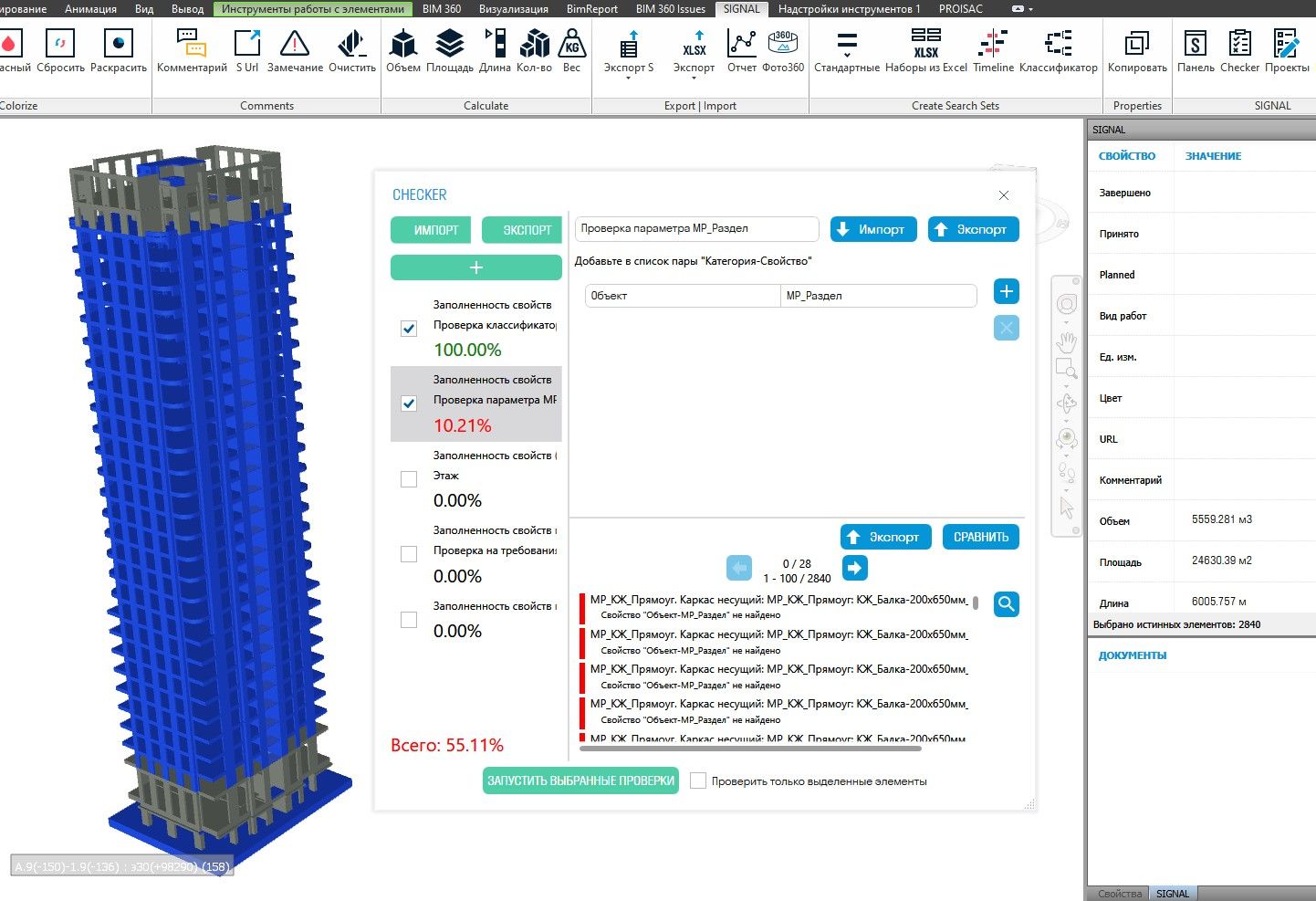
Рис. 1. Проверка элементов информационной модели и их атрибутивной информации
Далее BIMспециалист проверяет ИМ на коллизии, наличие необходимых элементов в модели согласно регламенту, дублирующиеся элементы и полноту обязательных параметров. Следующий уровень — проверить формат заполненных значений и их проектную корректность (рис. 2).
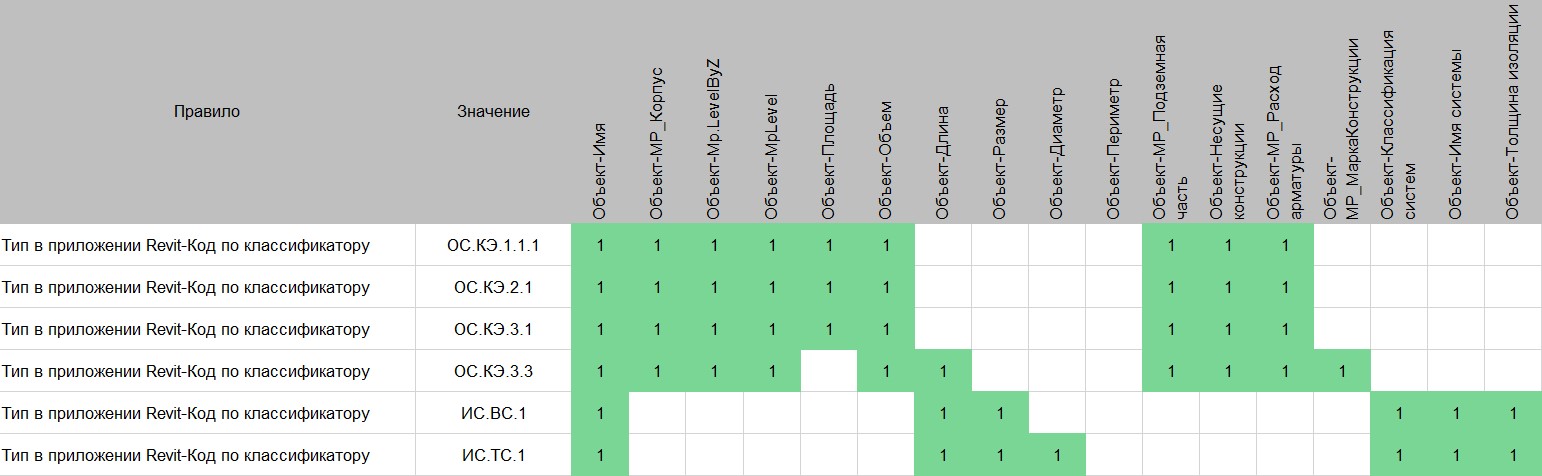
Рис. 2. Проверка информационной модели на полноту параметров
Такая верифицированная информационная модель может быть использована для получения объемов работ. Для этого должны существовать правила, в соответствии с которыми классификатор элементов связан с классификатором работ (однозначная таблица маппинга). Такой маппинг может быть описан в виде таблицы MS Excel или другого интерфейса.
Классификатор работ при этом берется из структуры WBS (Work Breakdown Structure), в которой ведется бюджет и контролируются сроки по календарносетевому плану проекта. В некоторых случаях он может до определенного уровня соответствовать структуре классификатора элементов, но в других вполне может отличаться (рис. 3).
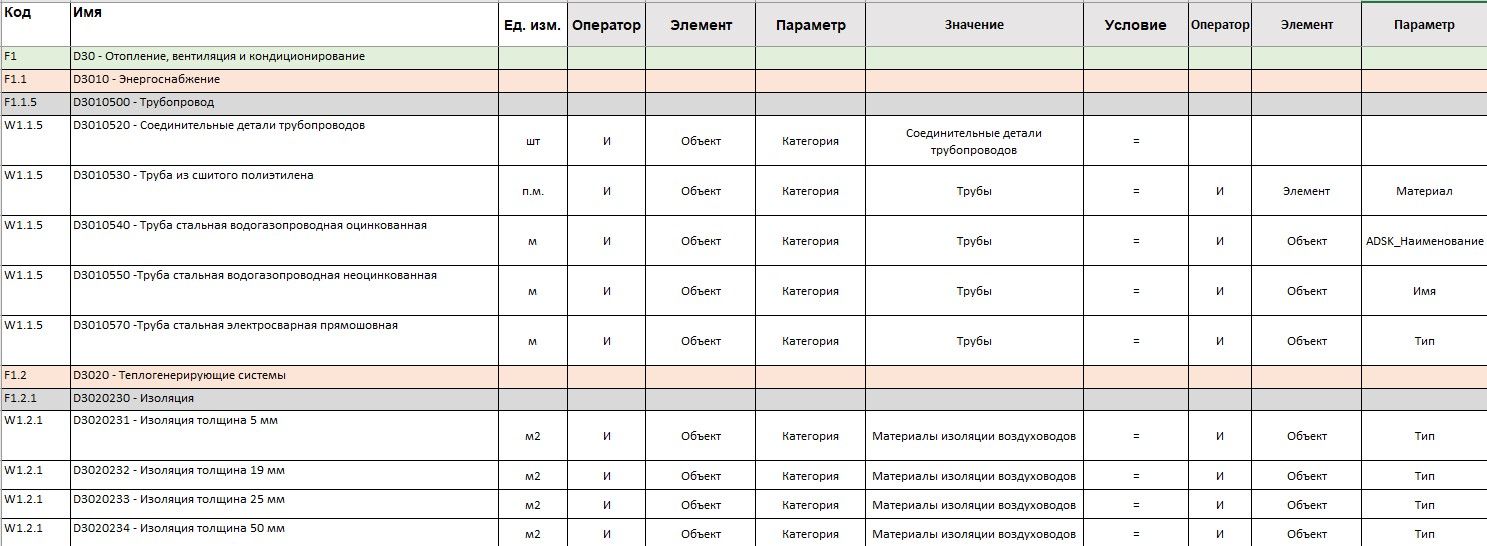
Рис. 3. Пример таблицы маппинга элементов и работ
Виды работ и сметы
Сметы по государственным или коммерческим расценкам некоторых девелоперов являются более детализированными, нежели виды работ. Поэтому они должны быть ассоциированы с видами работ в проекте, к которым они относятся и стоимость которых они формируют. Через маппинг видов работ и сметных позиций (не путать с маппингом элементов и работ) осуществляется связь сметы с календарным графиком и бюджетом. Для реализации маппинга смета должна быть составлена в структуре видов работ, что достигается расшивкой WBS до детализации сметных расценок в проекте.
При создании сметы, помимо генерации самой таблицы сметного расчета, сметные позиции должны быть внесены и в элементы ИМ с указанием правил подсчета объемов для каждого, то есть из каких параметров и в таких единицах брать количественные значения (в этом поможет код по классификатору элементов).
Сметы должны быть сформированы в структуре видов работ, которые являются заголовками групп у сметных позиций, с учетом структуры разбивки объекта на пакеты. Например, по секциям или выше нуля/ниже нуля. Это необходимо при работе с разными подрядчиками, когда необходимо включать значения в разные договора.
Для автоматизированной генерации сметы и заполнения сметных позиций в элементы ИМ необходимо иметь таблицу маппинга этих сметных позиций и элементов (может быть получена на основе двух предыдущих таблиц и основана на классификаторе элементов и параметрах, которые должны быть заполнены в них). Данные правила могут быть также описаны как в табличном редакторе, так и в отдельном интерфейсе. При этом для одного элемента может быть заполнено несколько сметных позиций (рис. 4).
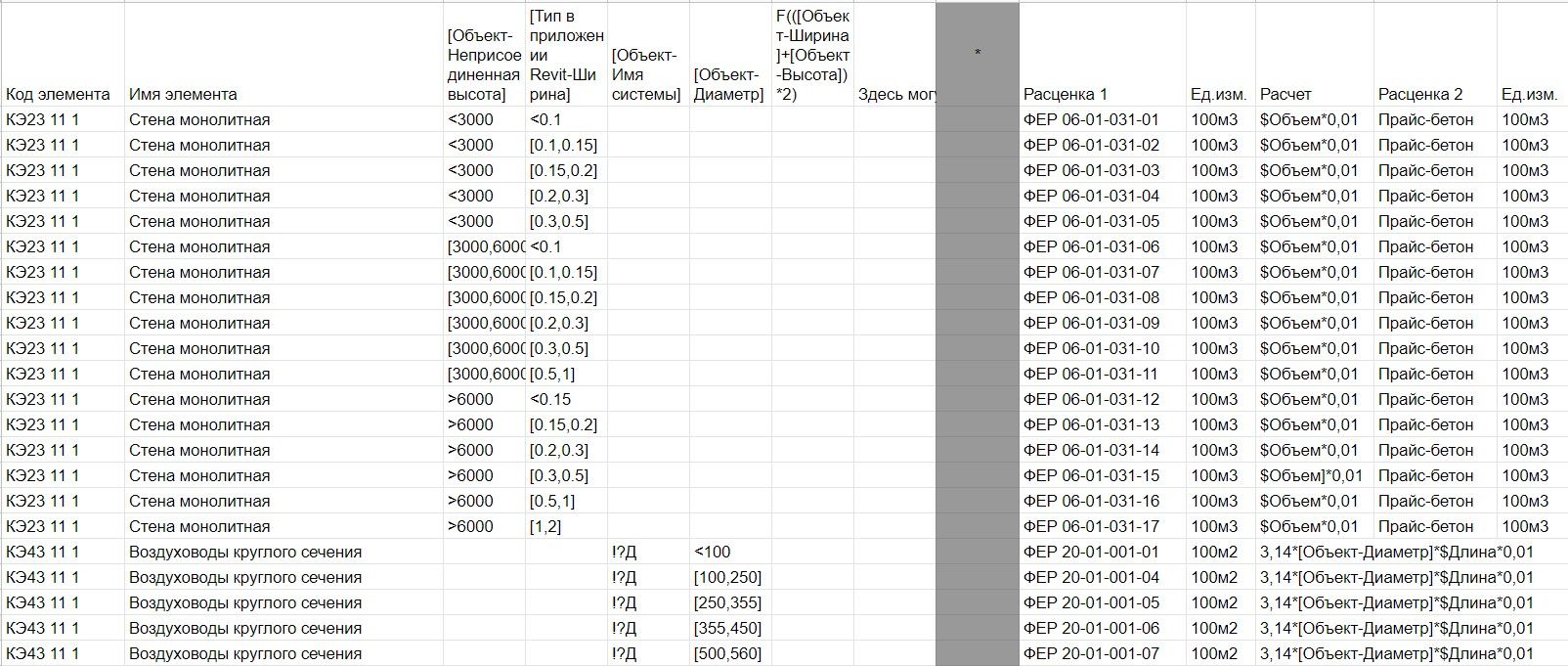
Рис. 4. Пример таблицы маппинга сметных позиций и элементов
В дальнейшем при проставлении отметки о выполнении работ на строительной площадке (выбор элемента ИМ и указание, что работы выполнены) пользователю выводится окно с выбором той работы, которая привязана к данному элементу и передала объем в сметную позицию (рис. 5).
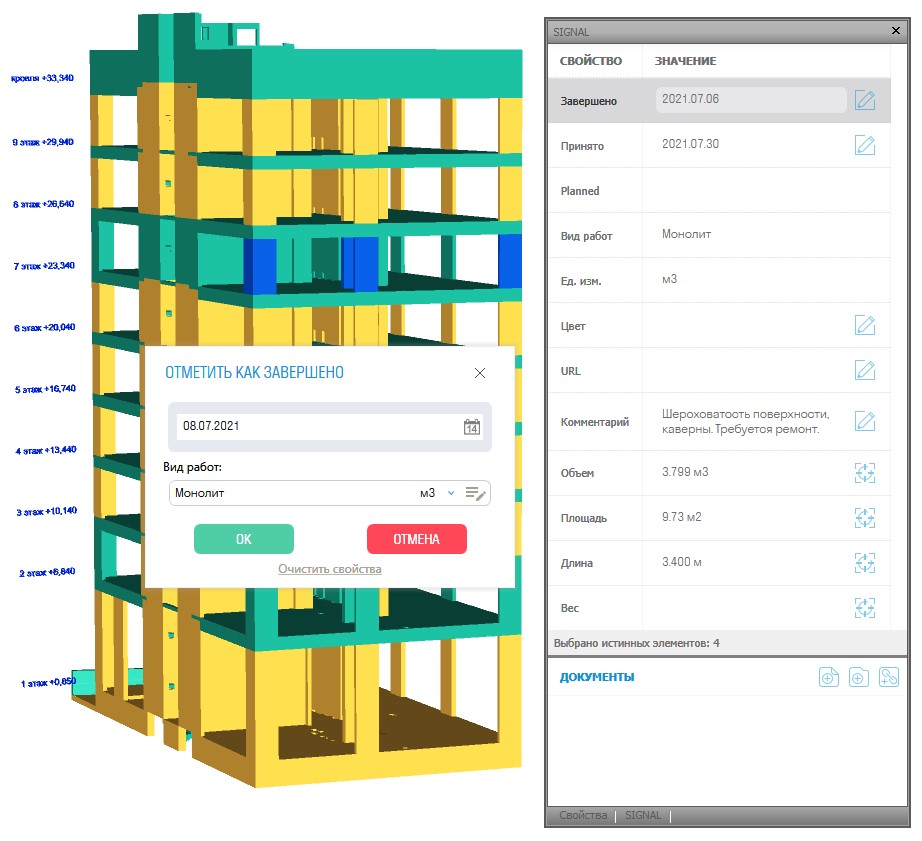
Рис. 5. Проставление отметки о выполнении работ на строительной площадке
Таким способом выполняется привязка статуса работ к сметным позициям (через объемы закрытых элементов ИМ), что позволяет генерировать формы КС2 и закрывать работы в цифровом виде (без бумаги).
По закрытым сметным позициям можно высчитывать стоимость закрытия каждого вида работ и вычислять процент освоения денежных средств по ним, а также находить процент выполнения и сравнивать с плановым по календарному графику.
Расчет количественных параметров
При подсчете количественных значений можно столкнуться с тем, что у различных элементов эти значения берутся из разных параметров. Это может быть связано с различным способом описания и моделирования элементов: наличия у них системных параметров или индивидуальных параметров проекта, которые вычисляются или автоматически в ПО, или с помощью разработанных плагинов, скриптов по определенным алгоритмам, например с учтенным запасом на усадку или подрезку. Кроме того, проблемы в таких расчетах могут возникнуть, если сводная ИМ или ИМ раздела получена из различного ПО, каждое из которых именует стандартные количественные параметры посвоему.
Казалось бы, один из самых очевидных путей для разрешения данной ситуации — создание отдельных параметров, которые будут заполняться вручную или скриптами во всех ПО, применяемых для разработки модели. Такой подход исключает использование системных количественных параметров этих продуктов моделирования, и как будто решает вопрос. Однако это может привести к еще большей нестабильности расчета: потребуются дополнительные проверки и пересчеты, а кроме того, повысится риск человеческой ошибки при вводе данных. Надо по максимуму стараться применять автоматически рассчитываемые системами параметры для большей стабильности в случае изменений.
Наиболее стабильным авторы считают подход с реализацией функции сумматора. В нем имеется возможность указания, какие параметры элементов брать при расчете и в каком порядке. Например, в одних элементах нужно брать параметр «объем» из вкладки Объект, параметра -> Объем, а у другого Element -> Volume, у третьего TeklaQuantity -> NetVolume, а у четвертого IfcBaseQuantities -> IfcVolume. Таким образом, из каждого элемента будет взят нужный для расчета объем, а в результате найден корректный суммарный, независимо от того, в каком ПО моделирования была разработана ИМ (рис. 6).
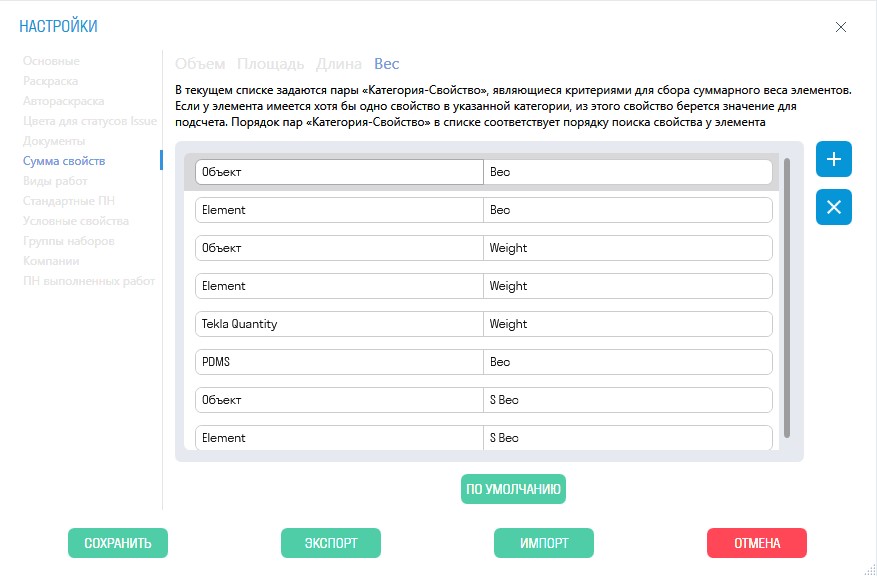
Рис. 6. Настройки сумматора свойств

