

Владимир Талапов —
признанный эксперт в области обучения и использования технологии информационного моделирования на российском и международном уровне, автор четырех учебников и более двухсот публикаций по теме BIM, президент
Сибирской БИМ-Академии
Современная российская практика показала, что главное препятствие на пути внедрения BIM — отсутствие мышления категориями информационного моделирования, причем на всех уровнях, от непосредственного исполнителя до министерского руководителя. Выправлению этого положения должна способствовать книга «BIM для начинающих», с содержанием которой мы начинаем знакомить наших читателей.
Введение
Прошедший год громко заявил о переходе строительной отрасли России на технологию информационного моделирования (ТИМ, во всем мире — BIM). Правда, дальше постановлений пока дело не пошло (отложено на июль 2024 года), но шумовой фон явно повысился.
Это хорошо, что строительство в России собирается выходить из долгой технологической спячки. Плохо, что процесс пробуждения больше напоминает броуновское движение, чем осознанное стремление к сформулированной цели. И главный показатель здесь — отсутствие ответа на вопрос: «Зачем всё это информационное моделирование делается?»
Как ни странно, это в итоге тоже хорошо: ведь если мы научимся на такой вопрос отвечать, а для начала даже просто правильно его формулировать, то наше движение к BIM станет гораздо эффективнее.
Так что главная задача на сегодня: научиться мыслить категориями информационного моделирования.
Несколько лет назад в нашей стране появилась книга, посвященная BIM, которая уже хорошо зарекомендовала себя в качестве учебника (Талапов В.В. Технология BIM: суть и особенности внедрения информационного моделирования зданий. М.: ДМКПресс, 2015). Однако жизнь не стоит на месте, технология развивается, а вместе с этим развитием высвечиваются новые запросы и проблемы. Так что возникла необходимость в новой книге, рассказывающей о BIM на более ранней стадии и помогающей научиться думать новыми категориями.
В результате коллектив авторов, признанных специалистов в области BIM (имена авторов будут названы чуть позже), сел за написание такой книги — «BIM для начинающих».
Предлагаем вниманию наших читателей вводную главу этой книги.
Информационное моделирование томатов как начало BIM
Давайте попробуем разобраться, что такое информационное моделирование, на хорошо знакомом, сравнительно простом и как бы понятном всем нам на бытовом уровне примере, причем далеком от тематики капитального строительства. Поговорим о помидорах.
Начинаем создавать информационную модель помидора
Итак, вводная информация: мы получили задание создать информационную модель помидора. Наша первая реакция — поднимаем голову и ищем глазами постановщика задачи, чтобы со смехом сказать: «Ну кто же так задания выдает?» Но на самом деле это не смешная, а вполне реальная ситуация, поскольку в строительстве задания на информационное моделирование в настоящее время примерно так и выдаются: «Сделайте нам BIM!» Более «продвинутый» вариант: «Сделайте нам BIM с LOD 350!» Или даже: «Сделайте Цифровой двойник!» Возможны и другие сходные по глубине понимания варианты, не далеко ушедшие от своего недавнего предшественника: «Сделайте нам проект в электронном виде!»
Так что получившему такое задание придется самому разбираться и догадываться, что это такое — информационная модель. С одной стороны, при такой постановке задачи вроде бы можно сделать всё, что захотим, и сказать, что это и есть информационная модель. С другой стороны, хочется всетаки сделать, как лучше, чтобы была польза. И вот тут на помощь должен прийти интеллект, причем не искусственный (о котором сейчас модно говорить), а наш собственный.
Итак, начинаем формировать информационную модель помидора.
Лучше всего, если бы при выдаче задания нам сразу сказали, для чего эта модель нужна и какие задачи с ее помощью планируется решать. Но у нас такой информации нет, так что будем думать сами.
Прежде всего надо понять, что мы собираемся моделировать: растения, плоды, процессы или вообще всё, что так или иначе связано со словом «помидор». То есть както правильно очертить и по возможности классифицировать круг объектов моделирования.
Для этого необходимо, как минимум, серьезно погрузиться в тему и разобраться в уже накопленных о помидорах знаниях. Поскольку мы понимаем, что наша задача — не получение новых сведений о помидорах, а систематизация и обработка уже имеющейся информации и объединение ее в некую общую и полезную для дальнейшей деятельности модель (рис. 1).

Рис. 1. После ограничения круга объектов моделирования растениями и их плодами мы с радостью узнаем, что определенная классификация в этой области уже существует. Это облегчает решаемую задачу
Поскольку модель информационная, то она должна содержать какуюто (конкретную, причем разнообразную) информацию о помидорах. Раз нам о количестве и содержании этой информации ничего не сказали, опять будем решать сами.
И здесь мы уже никак не можем пройти мимо списка решаемых с помощью создаваемой информационной модели задач. Так что начинаем определять эти задачи самостоятельно. Прежде всего выделим три основных направления деятельности: выращивание томатов, сбор и хранение урожая, переработка плодов для употребления (рис. 2).
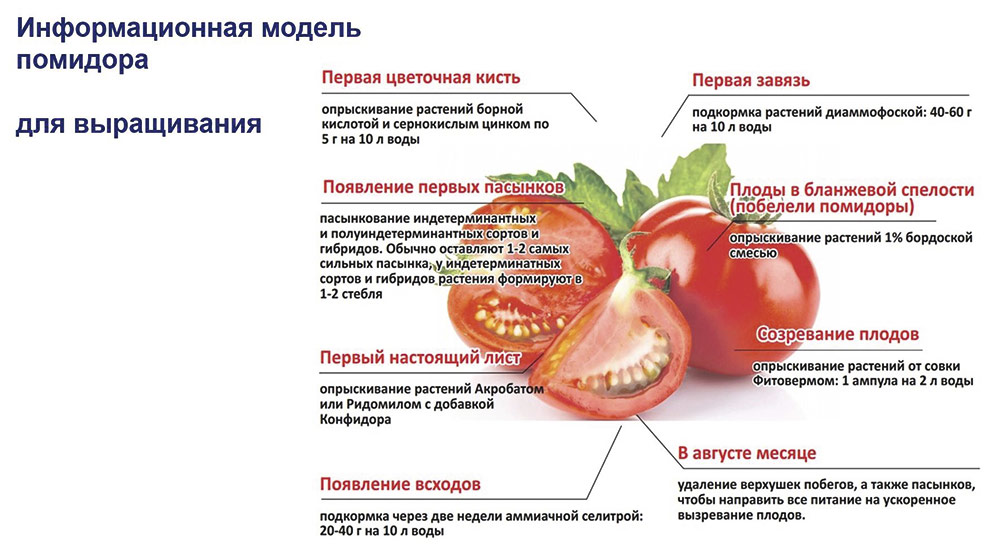
Рис. 2. Первый раздел информации в модели: сведения по выращиванию помидоров. Они связаны как с растениями, так и с плодами
Наша задача — собрать всю информацию по этим разделам, чтобы поместить ее в модель. Но такая задача практически не выполнима, во всяком случае, в короткое время — слишком долго будем искать и анализировать интересующие нас сведения, систематизировать их, придавать им «электронный» вид и распределять по ячейкам хранения. Это вполне может стать «делом всей жизни», даже в случае с помидорами, про которые мы вроде бы всё уже знаем. А нам надо завершить работу в разумное время.
Поэтому возникает понимание, что для начала достаточно собрать основную, наиболее востребованную информацию, но параллельно с этим разработать общую схему хранения этой информации, чтобы затем просто наполнять пустующие ячейки в модели дополнительными сведениями.
И перед нами снова встает вопрос о круге решаемых задач, поскольку мы должны понять, какая информация относится к основной, а также в каком виде (формате) мы ее собираемся в дальнейшем использовать (рис. 3).

Рис. 3. Второй раздел информации в модели — сведения по дозреванию и хранению — связан только с плодами
Еще один исключительно важный для нас вопрос: какие технические (компьютерные) средства мы будем использовать для создания нашей информационной модели. Ответ на этот вопрос существенно корректирует формируемые нами подходы по сбору и использованию информации, по ее видам, объемам и форматам электронного хранения.
И опять мы возвращаемся к заказчику, поскольку только он может окончательно определить, что ему подходит, а что нет, в том числе с учетом уже имеющихся у него компьютерных программ и методик работы. Либо он, развивая у себя информационное моделирование «с нуля» (сейчас это вполне типичная ситуация), отдает на наше усмотрение принятие всех основополагающих решений. Но даже в этом случае требуется его окончательное одобрение (утверждение) наших предложений (рис. 4).

Рис. 4. Третий раздел информации в модели — сведения по технологиям переработки и консервирования томатов — также связан только с плодами
Кроме перечисленных трех разделов, можно собрать еще много разной информации, например по заболеваниям и вредителям. Эта информация выглядит довольно обособленно, при этом она будет полезна как при выращивании, так и при хранении и даже переработке, так что она может представлять самостоятельный (четвертый) раздел в информационной модели.
Не менее интересен может быть «исторический» раздел будущей информационной модели. Ведь наша сегодняшняя культура разведения и использования томатов формировалась в течение длительного времени, а сами помидоры меняли свою географию произрастания. Например, еще в XVIII веке в Европе эти растения считались исключительно декоративными, а их плоды — ядовитыми.
Известно даже, что в 1776 году, во время войны североамериканских колоний за независимость, к Джорджу Вашингтону был подослан британский поварагент, который пытался отравить командующего повстанцев, приготовив ему к мясу соус из помидоров. У Джорджа Вашингтона в тот день была простуда, он не различал запахов, поэтому мясо и соус с удовольствием съел, а агент, боясь быть разоблаченным (ведь Джордж Вашингтон через несколько часов должен был с муками умереть), покончил с собой. А с Джорджем Вашингтоном, как мы знаем, ничего не случилось, он просто хорошо поел и даже выздоровел (рис. 5).

Рис. 5. Правдоподобность попытки отравления помидорами Джорджа Вашингтона при всем своем драматизме до сих пор вызывает у историков немало вопросов и сомнений
История интересная и к помидорам имеет самое непосредственное отношение. Хотя, видимо, по степени достоверности ее можно поставить в один ряд с ослеплением Иваном Грозным зодчих Бармы и Постника, чтобы они не смогли повторить Храм Василия Блаженного. То есть к мифам и легендам.
Опять же заказчик должен решать, нужна ли ему в модель эта информация. У нас же сразу возникает еще одно понимание, что вся помещаемая в модель информация должна быть достоверной, то есть гарантированно пригодной (без перепроверок) для дальнейшего использования. Только такой подход позволяет «автоматизировать» использование имеющейся в модели информации.
Но это не всегда возможно, причем по разным причинам. Так что появляется потребность, как минимум, в обязательной маркировке помещенных в модель данных специальными «бирками»: достоверно, предположительно, маловероятно и т.п. Причем это касается не только правдоподобности информации, но и оценки уровня ее проработки (детализации) и многого другого.
Другими словами, в информационной модели данные не просто раскладываются по отведенным ячейкам, но и получают оценку их качества.
Как быть с экономической информацией?
Любая деятельность по выращиванию, хранению, продаже и переработке томатов имеет обязательную хозяйственноэкономическую составляющую. Например, при выращивании помидоров обязательно понадобятся удобрения, средства агрохимии, а также грядки, теплицы, инструменты, специальные моторизованные средства и многое другое, что напрямую к томатам не относится, но является обязательными компонентами для решения поставленных задач.
Аналогично можно указать складские помещения, контейнеры, тару для перевозки, транспортные средства, а также оборудование и помещения для переработки и консервирования томатов — много того, что обеспечивает деятельность по хранению, транспортировке, продаже или переработке собранного урожая.
Для полноты картины по хозяйственной деятельности к этому добавляются зарплата сотрудников и всевозможные управленческие расходы. Собрав и проанализировав всё это, мы сможем получить (регулярно получать) финансовоэкономическую и организационноуправленческую картину нашей деятельности, уже осуществляемой или планируемой. В частности, будем своевременно и точно узнавать себестоимость нашей продукции и роль всех затрат в ее формировании. Это значит, что мы сможем анализировать результаты нашей работы и управлять ими.
Спрашивается, нужна ли такая информация в информационную модель помидора? И ответ опять же зависит от заказчика, от поставленной им задачи. Если его (на уровне ботаники) интересуют только сами томаты, то вряд ли такая информация понадобится. Но если его цель — организовать и управлять своей деятельностью (выращивание, хранение и переработка), связанной с помидорами, то такая информация просто необходима. И в этом случае название «информационная модель помидора» становится довольно условным, скорее это уже информационная модель томатного производства.
Если мы говорим про экономическую информацию, то возникает еще один, причем очень важный аспект, характеризующий качество информации в модели, — точность и актуальность помещенных данных. Например, если мы продаем помидоры, то нам надо знать цены на эту продукцию на разных торговых площадках, и эти цены обязательно должны быть в информационной модели. Но цены в период активного сбора урожая могут меняться каждый день (даже несколько раз в день), и мы просто физически не сможем их сначала узнавать, а потом заносить в наши информационные ячейки. Выход один — предусмотреть в модели интерактивный сбор такой информации, то есть подключить модель к электронным ресурсам интересующих нас торговых площадок и получать информацию в режиме «онлайн».
Подобным образом дело обстоит и с другой очень важной информацией: ежедневным отображением в модели текущего уровня спелости выращиваемого урожая. Но здесь интерактивная связь с теплицей может осуществляться лишь одним способом: работник визуально определяет уровень созревания томатов, а потом вручную вносит эти данные в информационную модель. Хотя весьма вероятно, что в будущем помидоры сами будут передавать информацию о своей степени зрелости в общую информационную модель.
Таким образом, наша фантазия привела нас к тому, что информационная модель помидора — это не просто структурированный набор сведений о выращиваемых томатах, но также и определенный инструмент получения подобных сведений. И это опять определяется заказчиком.
Информационных моделей помидора может быть несколько?
Теперь если мы соберем всё описанное нами в одном месте, то у нас получится поистине огромная общая модель, которую условно можно называть «Энциклопедией помидора», она будет содержать всю известную нам информацию о томатах и их производстве и при этом постоянно пополняться. А пользователь пусть сам решает, какая информация из модели ему нужна и что с ней делать…
Понятно, что в силу своей чрезмерной наполненности такая модель будет очень громоздкой и неудобной для работы с узкоспециализированными задачами. Например, тем, кто занимается транспортировкой и хранением плодов, вряд ли нужна история про Джорджа Вашингтона, хотя сама по себе эта информация очень интересна. Рецепты консервирования им тоже вряд ли понадобятся. При этом совершенно очевидно, что весьма востребованными для указанных специалистов будут графики вызревания тех или иных сортов томатов, температурный режим и другие особенности их хранения и перевозки.
Однако многое из этого совершенно не требуется при выращивании. Зато весьма полезными будут данные о погоде, в том числе и долгосрочные прогнозы. Поэтому уже в который раз отметим, что для более правильного и рационального выполнения нами порученной работы желательно заранее и предельно точно знать, для чего заказчику нужна заказанная им информационная модель помидора.
Здесь мы совершенно логично приходим к пониманию, что информационных моделей помидора может быть несколько. Например, модель для выращивания, для хранения и продажи, для переработки, общая — для «Энциклопедии помидора», а также любые другие разновидности модели, если они потребуются.
Называть их можно поразному. Но главное различие этих моделей — в специализированном подборе информации (только то, что надо, и ничего лишнего) согласно решаемым задачам, а также в используемом программном инструментарии, с помощью которого эти модели создаются и функционируют.
При этом в порядке замечания отметим, что никому из перечисленных нами участников «томатной тематики» не нужна точная трехмерная геометрия помидора — для всех указанных задач достаточно иметь фотографию растения или типичных плодов сорта (для общего ознакомления). Это же касается и цвета. А вот вкус и запах — очень важная для томата информация, но ее на сегодняшний день почти невозможно «цифровизировать». Так что вкус и запах мы сегодня поместить в информационную модель просто не сможем (только в виде текстового описания), но по мере развития компьютерных технологий эта проблема явно решится.
Таким образом, для построения информационной модели помидора от заказчика требуется точная формулировка, что в этой модели должно содержаться, или хотя бы адекватное описание задач, которые с помощью этой модели он собирается решать. А также информация по используемому или предполагаемому программному инструментарию.
Если же задач много и они переходят от одного исполнителя к другому, то из соображений прагматизма вполне допустимо создание нескольких «специализированных» информационных моделей. Либо, наоборот, создание общих моделей, если наборы задач взаимосвязаны.
А теперь — Цифровой двойник помидора
Казалось бы, с пониманием сути информационной модели помидора мы разобрались, чем весьма довольны. Но реальная жизнь гораздо интереснее, и она уже приготовила нам новое испытание: создать Цифровой двойник помидора. Уже не смеемся, а снова пытаемся понять, что же это такое: Цифровой двойник помидора и как можно полученное задание выполнить?
Поскольку мы уже научены информационному моделированию томатов, то у нас появляются вопросы: чем Цифровой двойник помидора отличается от его информационной модели (которая уже есть), но самое главное, опять — кому и зачем он, этот двойник, нужен?
Поскольку информационная модель помидора, наполненная технологической информацией, довольно хорошо помогает решать задачи, связанные с основной деятельностью — выращиванием и переработкой помидоров, то вполне логично предположить, что есть еще какието очень важные (даже более важные) вопросы, которые в область применения модели не попали.
Предполагаем, что к таким вопросам можно отнести работы по генетическому изменению сорта помидора с формированием у него новых, необходимых нам свойств и качеств. И такая работа тоже требует информационного моделирования, но уже биохимических свойств и процессов в растении, генетических связей и зависимостей, возможности управлять ими. То есть предполагается более глубокое проникновение в суть помидора — на молекулярном и генетическом уровне. Другими словами, моделируются уже жизненные процессы, а не просто свойства, связанные с растениями.
И вот такую модель помидора, информационную модель, но с добавленными новыми разделами (и удаленными ненужными), которая по сложности явно превосходят всё сделанное ранее, вполне можно назвать Цифровым двойником.
Но это наши догадки. При серьезной работе для построения Цифрового двойника помидора от заказчика опять требуется точная формулировка, что это такое, что там должно содержаться, или хотя бы адекватное описание задач, которые с помощью Цифрового двойника он собирается решать. В точности, как с информационными моделями. И если таких задач несколько и решаются они разными способами, то из соображений прагматизма опять вполне допустимо создание нескольких Цифровых двойников. Либо, наоборот, создание общего Цифрового двойника, если задачи имеют общую основу.
Наконец, напрашивается главный вывод: надо понимать информационное моделирование с его целями и задачами и именно с этого начинать моделирование — только тогда мы сможем построить нужное количество информационных моделей, отвечающих всем нашим запросам.
Теперь перейдем к информационной модели здания.
Здание — это не помидор!
Ранее на примере помидора мы получили довольно интересное, хотя и первоначальное понимание, что такое информационные модели и с чего надо начинать их создание. Поэтому может возникнуть мысль, что этих знаний хватит для перехода к информационному моделированию объекта капитального строительства, то есть здания или сооружения. Во всяком случае, многие в нашей проектностроительной отрасли именно так и думают. Однако сразу же придется разочароваться: строительные объекты — это не помидоры.
Отличие первое: продолжительность жизненного цикла строительного объекта
Казалось бы, что тут особенного, ведь у помидора тоже есть жизненный цикл. И мы его даже почти весь рассмотрели: выращивание, хранение, переработка. Для строительного объекта, если брать укрупненно, это будет практически то же самое: проектирование, строительство и эксплуатация. Однако первое принципиальное отличие состоит в длительности этих этапов: если для помидора весь жизненный цикл занимает примерно год, то для здания проектирование может идти несколько лет, строительство — тоже несколько лет, а эксплуатация — несколько десятков или даже сотен лет, то есть практически без конца (во всяком случае, обычной человеческой жизни может не хватить).
Почему это отличие становится принципиальным? Дело в том, что изза постоянно ускоряющихся темпов развития компьютерных технологий бывает довольно сложно сформулировать требования к компьютерным моделям на несколько лет вперед, а уж на десятки лет — просто невозможно. Уже сегодня довольно трудно прогнозировать, на каких принципах будут строиться компьютеры и компьютерные программы через 2030 лет, там все принципиально изменится. Поэтому если мы думаем, что созданная нами сегодня информационная модель будет в неизменном виде служить нам несколько десятков лет, то мы сразу обрекаем себя на техническое отставание, как бы «консервируясь» на уровне сегодняшнего дня, и на дальнейшую бесполезность нашей работы.
Второе отличие — внутренняя сложность и насыщенность этапов работы со зданиями и сооружениями. В частности, на этапе эксплуатации могут возникать периоды проектирования и строительства, связанные с реконструкцией или другими изменениями объекта, то есть просматривается явное возвращение к предыдущим этапам жизненного цикла. У помидоров такого не бывает.
Однако информационным моделированием зданий и сооружений заниматься надо, особенно на самой долгой, насыщенной стадии работы со строительным объектом — эксплуатационной.
Отличие второе: смена заказчика
Наш опыт моделирования помидоров уже подсказывал, что прежде всего необходимо получить максимально точное задание от заказчика. Но заказчики могут быть разные: одни выращивают, другие консервируют, третьи продают, четвертые едят и так далее. И у всех разные интересы и требования.
В строительстве дело обстоит подобным же образом. Но даже главный заказчик там может меняться. Например, официально стадиями проектирования и строительства руководит технический заказчик, а содержанием и управлением построенного объекта — эксплуатант. Причем эксплуатант предварительно формулирует техническому заказчику свои пожелания, касающиеся того, что он хочет получить в качестве построенного объекта. То есть один заказчик может взаимодействовать с другим.
При переходе между этапами жизненного цикла строительного объекта происходит смена как самих решаемых задач, так и их методов и инструментов решения, а также исполнителей. Поэтому говорить о том, что какаято заранее созданная модель здания всему этому полноценно удовлетворяет, будет просто неверно. Но, как уже говорилось, заниматься информационным моделированием надо, причем на всех стадиях жизненного цикла здания или сооружения. И в мире этим активно занимаются (рис. 6).
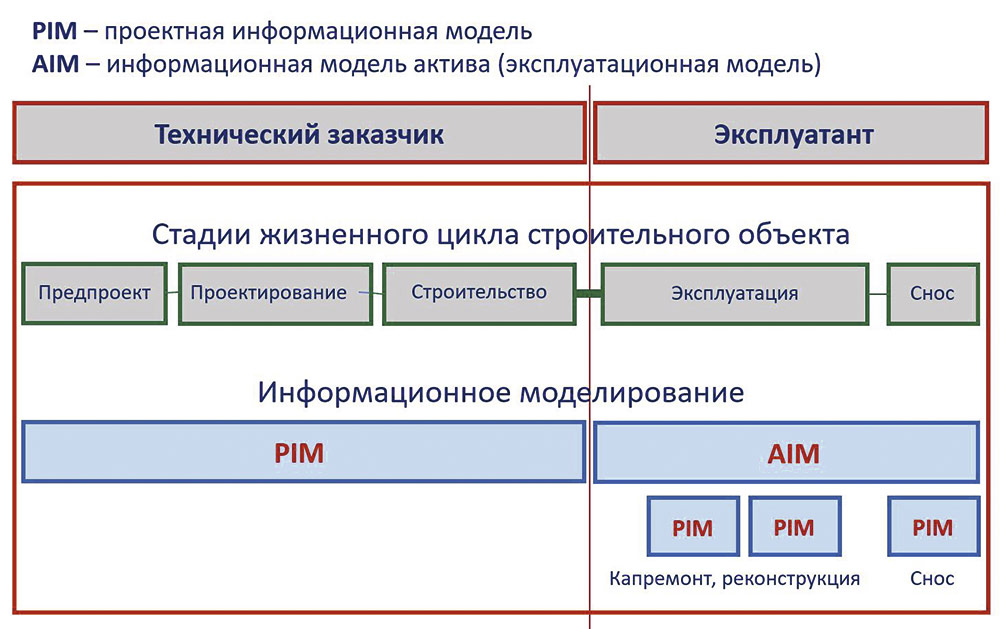
Рис. 6. Распределение функций заказчика на разных стадиях жизненного цикла строительного объекта
Отличие третье: трехмерная геометрия строительного объекта имеет очень важное значение
Как мы уже отмечали, трехмерная модель помидору не нужна: индивидуальная геометрия помидора в «томатной индустрии» практически никакого значения не имеет, в случае крайней необходимости можно просто добавить в информационную модель фотографию типичного плода и его усредненные параметры.
Для зданий и сооружений их геометрическое изображение — важнейшая часть сложившейся веками практики нашей работы. Причем создаваемая геометрическая модель индивидуальна для каждого объекта, она сразу несет в себе значительную информацию о здании, причем не только для зрительного восприятия, но и для многих видов расчетов. А в случае новых объектов их предполагаемая геометрия (проектная модель) появляется даже гораздо раньше самого объекта и затем может многократно корректироваться.
Однако надо понимать, что трехмерная модель здания — это не цель информационного моделирования в строительстве. Это — сложившаяся веками «визуализация» строительной информации, как при ее создании и помещении в модель, так и при дальнейшем использовании.
Отличие четвертое: необходимость моделирования процессов имеет более важное значение
Конечно, информация по процессам важна и для помидора, например по дозреванию. Но строительные объекты имеют более сложные технологические и управленческие процессы, которые изменяются под действием внешних параметров, часто происходят одновременно, и их модели можно использовать для прогнозирования свойств объекта или даже создания сооружения с нужными свойствами.
Отличие пятое: стадии жизненного цикла строительного объекта могут идти параллельно
В сельском хозяйстве продукт сначала выращивают, а уже потом едят. Однако из практики мы знаем, что для объектов строительства фактически процессы проектирования, возведения и использования сооружений могут идти почти одновременно. Конечно, с различными очевидными оговорками. Но могут.
Можно привести еще много других отличий здания от помидора, но уже этих вполне достаточно, чтобы понять, что информационное моделирование строительного объекта — дело сложное и комплексное, требующее серьезного понимания и инструментальных средств работы.
Прежде всего речь должна идти об определении и правильной постановке задач на каждой стадии, на каждом этапе работы с объектом, для решения которых необходимо применение технологии информационного моделирования. Эти задачи могут быть как локальные, не выходящие за рамки одного этапа или даже небольшого периода жизненного цикла объекта, так и более весомые, предполагающие длительный период для решения. Поэтому весьма распространенный тезис о том, что ТИМ (или BIM) — это создание некой информационной модели «на все случаи жизни», которая потом ходит по кругу и используется всеми участниками процесса работы с объектом, просто неверен, поскольку на практике нереализуем!
Единственно правильный подход — говорить об информационном моделировании на каждой стадии или на каждом этапе работы со строительным объектом. А создаваемая при этом информационная модель будет предназначаться для решения задач, возникающих на этих этапах, или даже являться следствием решения таких задач.
Таким образом, информационных моделей у объекта может быть много. Они либо переходят на следующий этап, с изменениями и дополнениями (например, модель здания «как построено»), либо остаются в рамках своего этапа (например, модель строительного контроля), но все они являются продуктами общего процесса информационного моделирования, определяемого связанными с этим объектом задачами.
В информационном моделировании первичен процесс, а модели, как результаты этого процесса, имеют подчиненное положение. Такое понимание поможет методически правильно выстроить процесс информационного моделирования и сделать его экономически эффективным.

