
Голосовые интерфейсы приобретают всё большее распространение. Они позволяют сделать технологии более доступными и расширить область их применения. Помимо голосовых ассистентов общего назначения, устанавливаемых в смартфоны и умные колонки, разрабатываются голосовые помощники, работающие в отдельных областях [1]. Данная статья относится к разработке голосового помощника комплекса управления узлом связи специального назначения.
Необходимым компонентом любого голосового помощника является система распознавания речи. В настоящее время наилучшие результаты в области распознавания речи показывают глубокие нейронные сети. Однако в их применении существуют некоторые ограничения: значительные ресурсы, необходимые для обучения и применения, ограничение словаря распознаваемых слов. В данной статье рассматривается возможность использования публично доступных библиотечных решений для распознавания речи в голосовом помощнике комплекса управления узлом связи специального назначения (рис. 1). Производится оценка точности и вычислительной эффективности моделей, учитывается существование специфических слов в области связи специального назначения, а также влияние шума различной интенсивности на качество работы моделей.
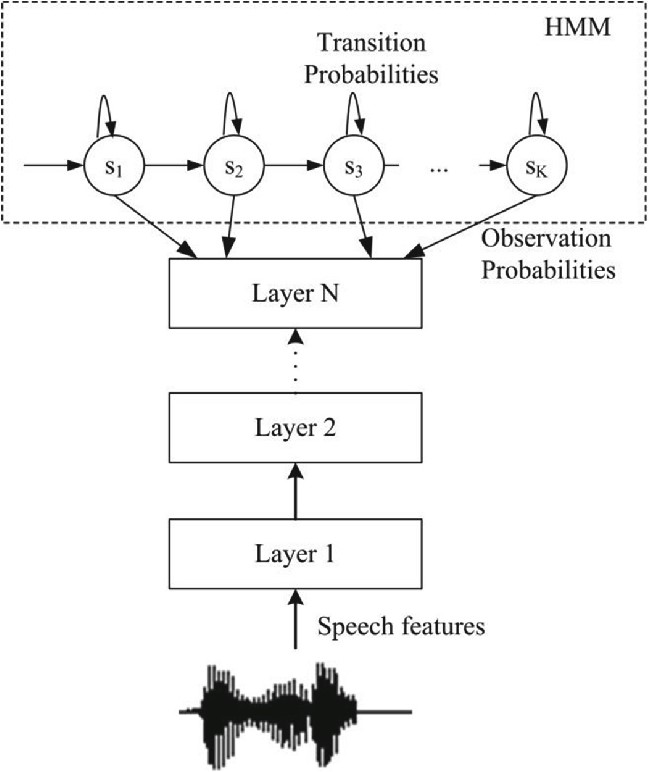
Рис. 1. Интерфейс голосового помощника комплекса контроля и управления узлом связи специального назначения
Из-за большого объема ресурсов, необходимых для обучения нейронных сетей, рассматривались только библиотеки, предлагающие предобученные модели с доступным весом и достаточно низкими требованиями к вычислительным ресурсам для выполнения. Такие модели предлагает библиотека с открытым исходным кодом (лицензия Apache-2.0) Vosk [2, 3]. Она содержит большие модели для выполнения на сервере, а также малые модели для запуска на мобильных устройствах. В данной работе рассматриваются серверные и мобильные модели разных версий: более новые серверная модель vosk-model-ru-0.22 и мобильная vosk-model-small-ru-0.22, а также более старые vosk-model-ru-0.10 и vosk-model-small-ru-0.4. Данные модели имеют архитектуру DNN-HMM, сочетающую глубокие нейронные сети со скрытыми марковскими моделями (рис. 2).
Рис. 2. Архитектура DNN-HMM (Источник: [5])
Для оценки качества моделей были использованы части датасета OpenSTT [3] проекта Silero. Датасет OpenSTT содержит записи речи с транскрипцией из разных источников. Для данной работы были использованы разделы с фрагментами видео с YouTube, сериалов и лекций.
OpenSTT имеет достаточный объем для того, чтобы точно оценивать качество моделей на типичных записях. Однако в нем не представлена специфичная для связи специального назначения лексика. Поэтому для оценки работы моделей был создан свой датасет, состоящий из команд, поддерживаемых разрабатываемым голосовым помощником. Он содержит 45 команд, каждая из которых была записана тремя говорящими.
Поскольку эксплуатация в условиях узла связи специального назначения не позволяет рассчитывать на тишину при использовании голосового помощника, от его модели распознавания речи требуется устойчивость к шуму. Для оценки этого свойства моделей каждая запись оценивалась как в изначальном виде, так и с белым гауссовским шумом, добавляемым с соотношением «сигнал/шум» в 10 и 5 децибел.
Ограничениями использованных датасетов являются гауссовское распределение добавляемого шума, которое может быть недостаточно репрезентативным относительно реального шума, а также ограниченные объем записанного датасета и разнообразие голосов в нем.
Распространенной метрикой качества автоматического распознавания речи является WER (word error rate — доля слов с ошибками). Она определяется как
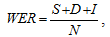 , (1)
, (1)
гдe:
S — количество замен слов,
D — количество пропущенных слов,
I — количество добавленных слов,
N — длина произнесенной фразы.
Такая метрика подходит для приложений, где распознанный текст может быть исправлен с помощью клавиатуры, поскольку отражает количество требуемых исправлений, но может вводить в заблуждение в других случаях. Например, она зависит от длины выходной фразы. Так, если все слова распознаны неправильно, добавление лишних слов будет увеличивать WER, хотя количество полезной информации в любом случае будет нулевым.
Метрика MER (match error rate) исправляет проблемы WER, связанные с длинами входной и выходной последовательностей. Она определяется как отношение числа слов ошибок к общему числу слов (правильно распознанных, замененных, потерянных и добавленных):
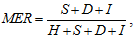 , (2)
, (2)
гдe:
S — количество замен слов,
D — количество пропущенных слов,
I — количество добавленных слов,
H — количество правильно определенных слов.
Метрика RIL (relative information lost) характеризует информацию
о целевой фразе, содержащуюся в получаемой с помощью модели транскрипции. Она определяется как отношение условной энтропии целевой фразы относительно полученной транскрипции к энтропии целевой фразы. WIL (word information lost) вычислительно эффективно приближает RIL:
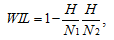 , (3)
, (3)
где:
H — количество правильно определенных слов,
N1 — длина целевой фразы,
N2 — длина полученной фазы.
В голосовом помощнике после распознавания речи производится определение команды. У каждой команды есть одна или несколько ключевых фраз-триггеров. После распознавания фрагмента речи пользователя вычисляется редакционное расстояние Левенштейна до каждой из ключевых фраз, и выбирается команда, триггер которой минимизирует данное расстояние. Поэтому, чтобы оценить качество распознавания речи с точки зрения голосового помощника, вычисляется посимвольное нормализованное расстояние Левенштейна (NLD). Нормализация через деление расстояния на максимум из длин оригинальной и распознанной последовательностей применяется для выравнивания влияния последовательностей различной дины и упрощения интерпретации (наихудшее значение равно 1).
Для более точной оценки определения команды была использована метрика Precision@1. Она вычислялась только по датасету команд. Для ее вычисления для каждого транскрипта выбирается ближайший по расстоянию Левенштейна текст команды. Метрика Precision@1 равняется доле транскриптов, для которых ближайшим текстом является правильный.
На рис. 3 представлены графики метрик моделей на OpenSTT, на рис. 4 — на нашем датасете из команд голосового помощника. Новая компактная модель vosk-model-small-ru-0.22 показывает результаты на уровне старой серверной vosk-model-ru-0.10 при умеренном шуме, а на датасете команд и вовсе превосходит ее. Новая большая модель показала неожиданно низкие результаты. Ручной анализ транскриптов показал, что такие результаты связаны с запаздыванием текста: при последовательной подаче на вход модели различных записей часть более ранней записи остается в памяти модели и попадает в результат распознавания следующей записи.
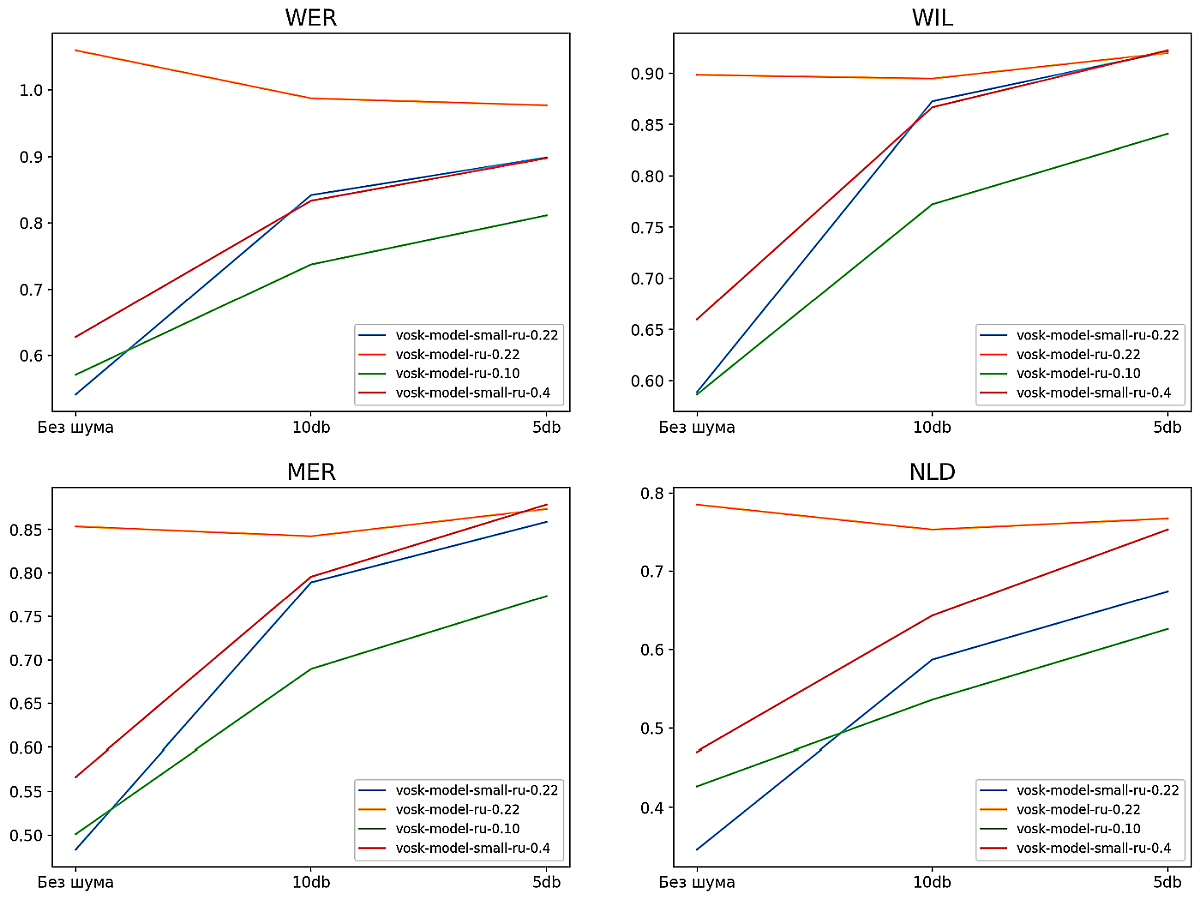
Рис. 3. Метрики моделей на датасете OpenSTT
Для оценки производительности моделей вычислялось отношение времени работы модели ко времени записи. Результаты приведены в таблице, из которой мы видим, что серверные модели выполняются примерно за половину времени аудиозаписи, а мобильные — за десятую долю, что может оказать существенное влияние на пользовательский опыт в части задержки ответа.
Табл. Отношение времени работы моделей на аудиозаписях к длине этих записей
Модель |
Отношение времени |
vosk-model-small-ru-0.22 |
0,095 |
vosk-model-ru-0.22 |
0,52 |
vosk-model-small-ru-0.4 |
0,082 |
vosk-model-ru-0.10 |
0,452 |
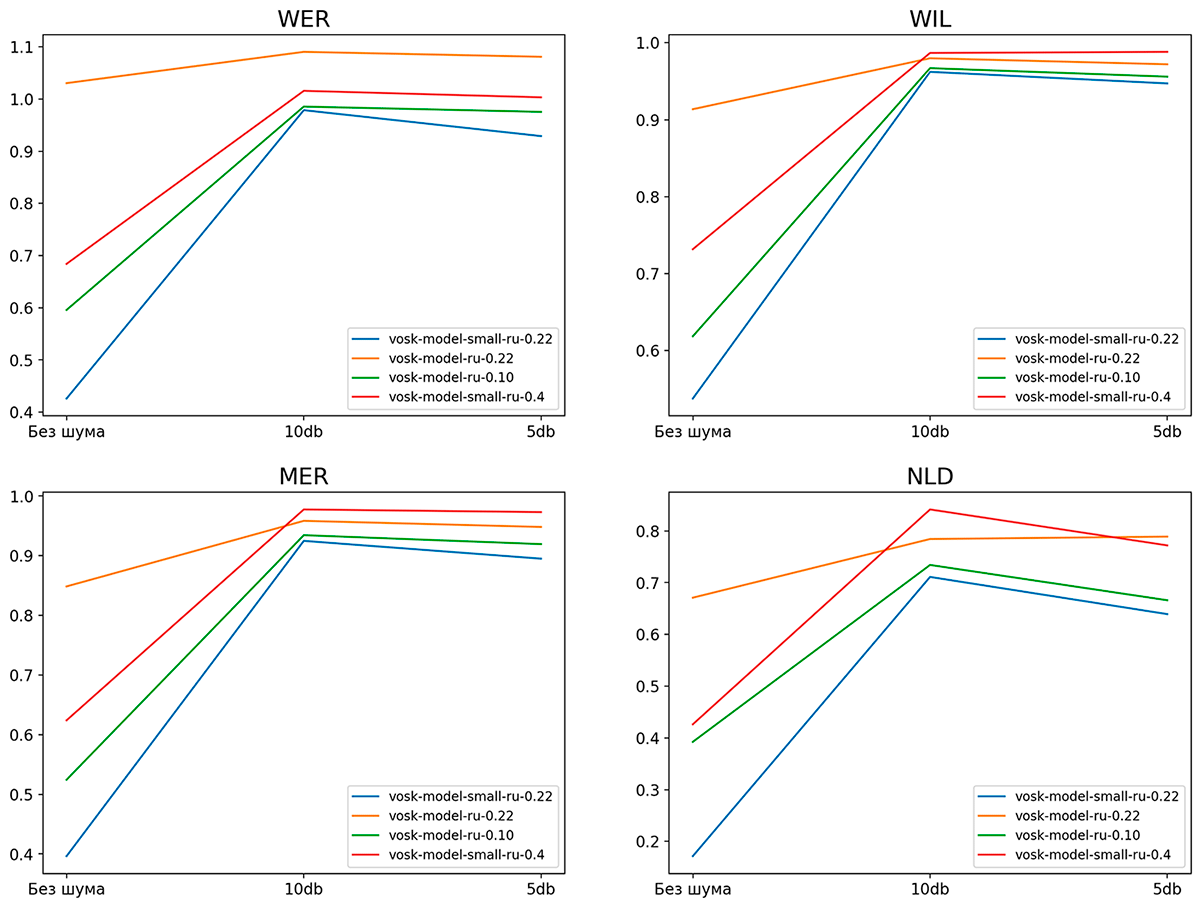
Рис. 4. Метрики моделей на датасете команд голосового помощника
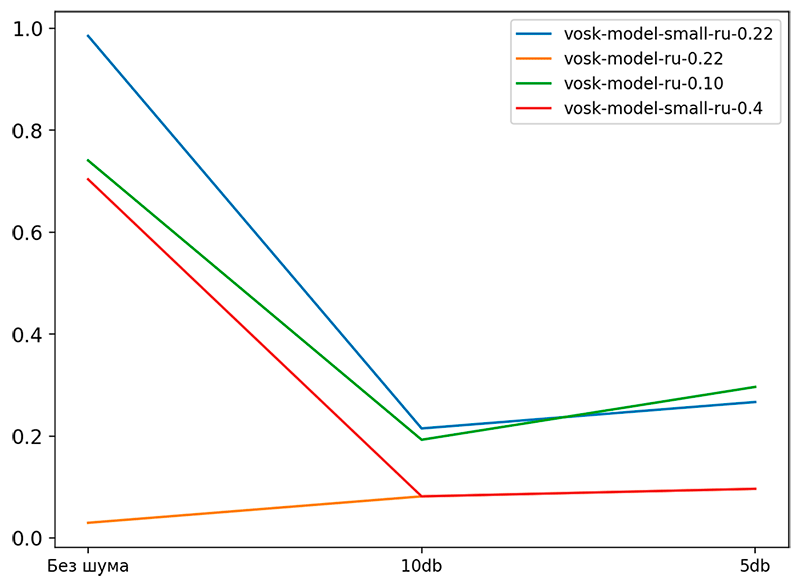
Рис. 5. График Precision@1 различных моделей в зависимости от уровня шума
На рис. 5 представлены значения метрики Precision@1 для различных моделей в зависимости от уровня шума. Новая мобильная модель показывает результаты, близкие к старой серверной модели или лучше, особенно при низком уровне шума.
В данной статье рассмотрены модели для распознавания речи из библиотеки с открытым исходным кодом Vosk с точки зрения разработки голосового помощника для управления узлами связи специального назначения. Были использованы общедоступный датасет OpenSTT — для оценки общего качества моделей, а также свой датасет — для оценки качества работы моделей с текстами, содержащими специфичную для предметной области лексику и расчета метрики Precision@1, отражающей точность определения команды. Новая мобильная модель vosk-model-small-ru-0.22 показала высокие метрики, особенно на датасете команд голосового помощника при малом потреблении ресурсов и признана оптимальной для дальнейшего использования.
Источники:
- Иванов В., Черенкевич М., Масевцев А., Андриенко М. Голосовые помощники в системе принятия решений на основе искусственного интеллекта // САПР и графика. 2021. № 2 (292). С. 60-63.
- Документация Vosk — https://alphacephei.com/vosk/
- Датасет OpenSTT — https://github.com/snakers4/open_stt
- Wang Y., Acero A., Chelba C. Is word error rate a good indicator for spoken language understanding accuracy, 2003 IEEE Workshop on Automatic Speech Recognition and Understanding.
- Morris A., Maier V., Green P., From WER and RIL to MER and WIL: improved evaluation measures for connected speech recognition, ITERSPEECH, 2004.
На сайте используется Яндекс метрика
Мы в:  и
и
