

Лев Шаповалов, начальник отдела ПАО «ОАК»

Илья Танненберг,
руководитель группы по направлению CAE,
Ланит-Технологии, Департамент ЦТМ

Владимир Печников, ведущий специалист отдела внедрения ЗАО «Топ Системы»
Система T-FLEX Управление требованиями, разработанная компанией «Топ Системы», является мощным инструментом, предназначенным для автоматизации процессов управления требованиями и повышения эффективности разработки сложных изделий в рамках PLM-систем. В функциональность T-FLEX RM входят сбор, анализ, согласование и утверждение требований, а также контроль их выполнения на всех этапах жизненного цикла изделий. Система поддерживает различные типы требований и работает со множеством форматов записи данных.
При апробации программного продукта T-FLEX Управление требованиями в компании ПАО «ОАК» была поставлена задача, которую необходимо было решить для наиболее эффективного процесса управления требованиями. Эта задача была связана с ограничениями концентрации внимания и скорости обработки текста у пользователя, особенно при работе с большим количеством требований.
Идея
На практике требования меняются от версии к версии. Это объясняется постоянным обновлением и дополнением документов для соответствия их актуальным требованиям и стандартам. Кроме того, требования могут быть изменены внутри одного документа, например при перенесении в другой раздел или редактировании текста с сохранением смысла. Важно следить за согласованностью и своевременным документированием всех изменений в требованиях, для того чтобы сохранялась целостность документации.
В таком бизнес-процессе требуется инструмент, предоставляющий пользователю возможность работать над задачами управления требованиями более продуктивно. Рассмотрим предназначенные для этого известные инструменты.
Текстовые редакторы обладают функцией сравнения записей. Механизмы редакторов осуществляют сравнение по формальному признаку на основе разницы во фрагментах слов, учитывая регистр и пробелы, однако эти механизмы не способны оценить сходство предложений на уровне смысла.
Онлайн-ресурсы, такие как поисковые системы, социальные сети, форумы и блоги, имеют инструменты для поиска схожих текстовых фрагментов. Эти инструменты основаны на более продвинутых алгоритмах и применяют анализ ключевых слов, синтаксический анализ и сравнение структуры предложений. Например, для поиска похожих текстов Яндекс использует алгоритмы, основанные на ключевых словах и анализе структуры предложений. Существенным ограничением открытых онлайн-сервисов является их полная неприменимость в работе с информацией ограниченного доступа.
NLP (natural language processing) — это бурно развивающаяся дисциплина в области искусственного интеллекта, занимающаяся обработкой естественного языка и имеющая множество практических приложений. Одним из главных прорывов в этой области стало появление технологии Embeddings.
Embeddings — это способ представления слов и других языковых единиц в виде одномерных массивов чисел, позволяющий решать задачи машинного обучения на текстах.
Машинный анализ требований является одним из важнейших направлений в NLP. Он автоматически извлекает требования из текста и представляет их в виде структурированных данных, что облегчает обработку и понимание информации. Это помогает разработчикам создавать более качественные продукты. Сегодня существует несколько инструментов для машинной обработки текстов: LABSE, Sentence BERT, InferSent, Universal Sentence Encoder (USE). В компании ПАО «ОАК» был сделан выбор в пользу LABSE.
LABSE (Language Agnostic BERT Sentence Embedding) — это модель машинного обучения, которая используется для создания векторного представления предложений. Она применяется для решения различных задач, таких как классификация предложений, поиск похожих предложений и т.д.
Реализация
В начале 2022 года стартовала работа по выявлению дополнительных потребностей для улучшения работы пользователей с системой T-FLEX Управление требованиями. За основу прототипа новой утилиты были приняты алгоритмы LABSE. Схема архитектуры LABSE представлена на рис. 1. В ходе работы проводились изменения в T-FLEX DOCs, разрабатывались макросы, настраивались диалоги и дополнительные сущности.
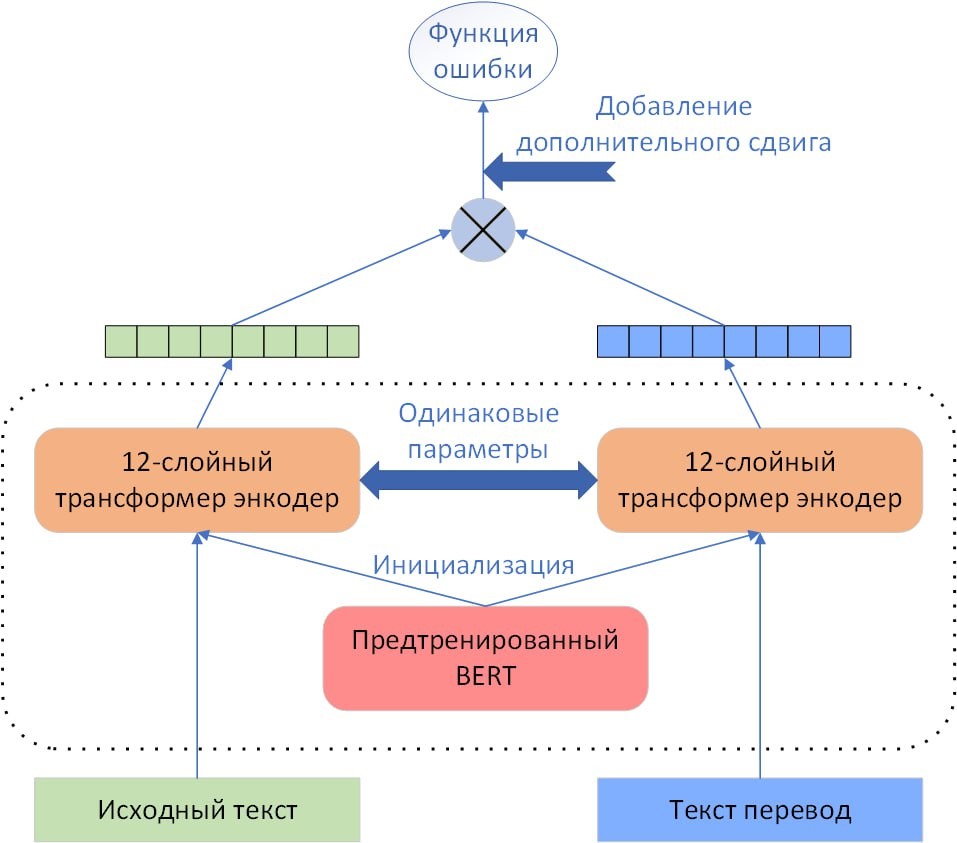
Рис. 1
Кроме того, был проведен ряд экспериментов на площадках ПАО «ОАК». На рис. 2 и 3 представлены примеры результатов работ.
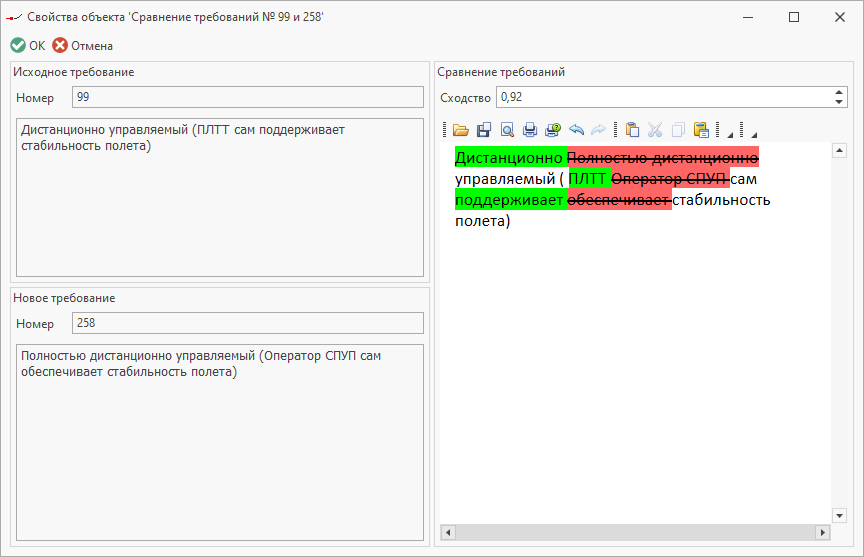
Рис. 2
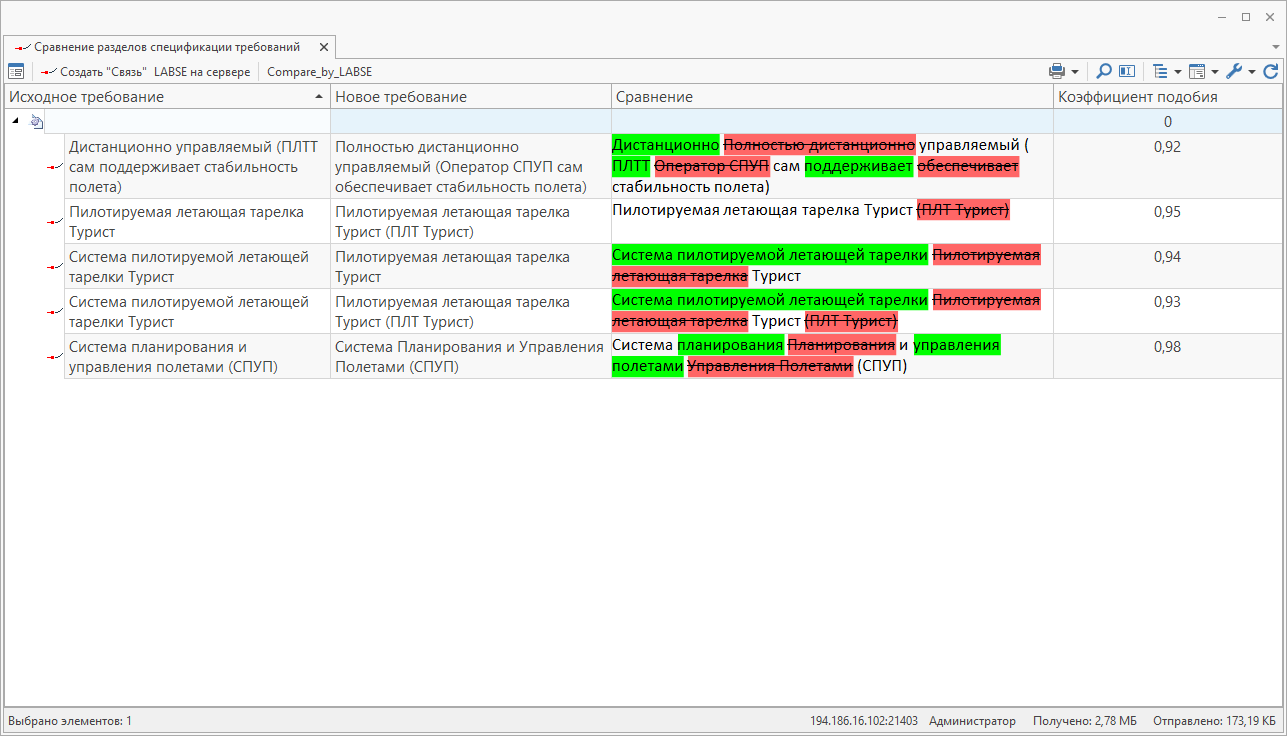
Рис. 3
В итоге система стала позволять пользователю не просто сравнивать информацию в разных источниках, а видеть взаимосвязь между требованиями, которые предъявляются к объектам или процессам. Можно сказать, что система читает текст, который на 150% больше стандартного. Коэффициент подобия помогает пользователю оценить связь требований между собой.
Результаты
Сотрудниками ПАО «ОАК» были подобраны оптимальные коэффициенты сходства для работы алгоритма, чтобы он обрабатывал большие объемы данных и выдавал точные результаты. Например, значение коэффициента больше 0,8 означает, что требования похожи друг на друга. Это помогает определить сходство или различие требований двух разных текстов с высокой скоростью, в автоматизированном режиме, с учетом возможного парафраза и перестановок частей текста.
Решилась задача ускорения работ с ТЗ и ЧТЗ путем оптимизации процесса анализа трассировки. Это позволило сократить затрачиваемое время и повысить эффективность работы.
Кроме того, был проведен анализ нормативных документов и увеличена скорость обработки, что позволило более эффективно проводить аудит. В ходе работ также нашлись дублирующиеся части внутри одного текста, поэтому в дополнение проводился анализ потенциально скрытых связей на низких порогах коэффициента сходства.
Теперь при анализе отчетов система работает в режиме «антиплагиат» для определения частей, взятых из предыдущих отчетов по другим темам. Пользователь ищет противоречия путем сравнения похожих требований и при необходимости передает их на анализ специалистам, чтобы убедиться, что они не содержат значимых различий.
Перспективы
Сотрудники ПАО «ОАК» видят, что в будущем будет формироваться удобное для использования серверное решение, позволяющее уйти от проблем лицензирования. Достичь этого планируется путем разработки собственной архитектуры, применения существующих коммерческих решений или сочетания обоих подходов.
Кроме того, будет продолжено обучение нейронной сети на специфических текстах и осмысление сокращений в совокупности с определениями для улучшения качества продуктов и услуг предприятия.
Эксперимент по внедрению искусственного интеллекта в процесс управления требованиями признан успешным. В настоящее время он расширяется на предприятиях Роскосмоса. В следующей статье будет рассказано, как на основе существующего инструмента осуществляется анализ полноты декомпозиции требований.

