
Тестирование аппаратно-программного комплекса R-Style Marshall EP272r и CFX-5 на задачах вычислительной аэродинамики
Аппаратные и программные средства
В настоящее время все большее распространение получают вычислительные системы на базе процессоров Intel Itanium 2, что связано с их высокой производительностью, большим объемом доступной оперативной памяти и хорошей масштабируемостью многопроцессорных вычислительных систем. Такая масштабируемость позволяет проводить с высокой точностью сложные научные и инженерные расчеты, существенно сокращая сроки проектирования и доводки изделий.
Предлагаемое вашему вниманию тестирование ставило своей целью сравнить производительность вычислительных систем на базе процессоров Intel Itanium 2 (64-разрядная архитектура) и Intel Xeon (32-разрядная архитектура) при решении сложных и ресурсоемких задач аэродинамики. Исследования выполнены кафедрой компьютерного моделирования факультета аэромеханики и летательной техники (МФТИ) (www.mipt.ru) на базе созданного на факультете центра параллельных вычислений (грант РФФИ 02-07-90475-В) совместно с компанией R-Style Computers (российский производитель многопроцессорных систем и кластеров, www.r-style.computers.ru), Компанией R-Style (ведущий российский системный интегратор, www.r-style.com), инжиниринговой компанией «ТЕСИС» (российский производитель и дистрибьютор инженерного программного обеспечения, www.tesis.com.ru) и инжиниринговым центром ОАО «Криогенмаш».
Методические расчеты включали исследование производительности и эффективности аппаратно-программного комплекса, состоящего из предоставленного компанией R-Style сервера R-Style Marshall EP272r на базе процессоров Intel Itanium 2 и программного комплекса ANSYS CFX-5 (разработка компании ANSYS, Inc., www.ansys.com). Исследование производительности вычислительных систем проведено с помощью предоставленного компанией «ТЕСИС» комплекса автоматизированного инженерного анализа CFX-5, предназначенного для решения широкого круга задач вычислительной аэро- и гидродинамики.
Основным изучаемым параметром была масштабируемость программно-аппаратного комплекса, то есть зависимость времени счета от числа процессоров и объема задачи.
Аппаратные и программные средства
Для сравнения производительности и эффективности аппаратно-программных комплексов вычисления проводились на следующих вычислительных платформах:
• 64-разрядная вычислительная система R-Style Marshall EP272r (2xIntel Itanium 2 1,4 ГГц, 8 Гбайт RAM) под управлением ОС Red Hat Enterprise Linux 2.1;
• 32-разрядная вычислительная система Compaq Evo W8000 (2xIntel Xeon 1,7 ГГц, 2 Гбайт RAM) под управлением ОС Microsoft Windows 2000 Professional;
• 32-разрядный кластер, включающий четыре двухпроцессорных вычислительных узла на базе процессоров Intel Xeon 2,8 ГГц с 2 Гбайт RAM на узел с системой межпроцессорного обмена данными FastEthernet 100 Мбит/с под управлением ОС Red Hat Linux 7.3.
Такое сравнение позволяет оценить возможности процессоров Intel Itanium 2 для решения реальных инженерных задач и сопоставить производительность нового аппаратно-программного комплекса с производительностью известных комплексов.
Программный комплекс CFX-5 позволяет решать широкий круг задач с высокой параллельной эффективностью, поддерживая работу с гомогенными и гетерогенными параллельными вычислительными системами. CFX-5 дает возможность различными способами разбивать расчетную область на подобласти, которые размещаются на отдельных процессорах (узлах).
Основные возможности проведения распределенных вычислений, реализованные в CFX-5:
• масштабируемость по производительности и по оперативной памяти;
• работоспособность на всех основных вычислительных платформах;
• идентичность результатов на последовательных и параллельных платформах;
• простота использования и надежность.
Вышеперечисленные возможности реализованы за счет использования следующих принципов:
• разбиение и распределение расчетной области между процессорами;
• поддержка компьютеров с общей и распределенной памятью;
• единый пре- и постпроцессор для последовательных и параллельных вычислений;
• единая программа для расчета на последовательных и параллельных платформах;
• встроенные библиотеки передачи данных между процессорами (PVM, MPI).
Тестирование, проведенное разработчиками комплекса CFX-5, показало его хорошую масштабируемость на кластерах, содержащих до 64 процессоров и более.
Модельная задача
Модельная задача представляет собой задачу внешнего обтекания фургона, находящегося над поверхностью дороги. Габариты фургона — 5,22x1,945x1,44 м. Фургон расположен над поверхностью на высоте 0,25 м. Поскольку задача симметричная, то расчеты проводились в области, включающей половину тела (с условиями симметрии) и имеющей габариты 30x5,15x5 м. Вид геометрии тела и расчетной области представлен на рис. 1. Анализируется вязкое турбулентное течение воздуха около фургона при скорости потока 15 м/с. Физические и механические особенности задачи состоят в определении поля течения в потенциальной части потока, в пограничных слоях, в отрывных и вихревых областях.
Для моделирования турбулентных процессов применялась модель турбулентности SST с автоматическим выбором пристеночных функций. Модель турбулентности SST, разработанная и реализованная специалистами CFX, рекомендуется для инженерных расчетов течений с отрывными зонами.
В качестве начальных условий задачи используются следующие: начальная скорость потока (15 м/с), нормальное атмосферное давление (101 325 Па), температура (15 °С).
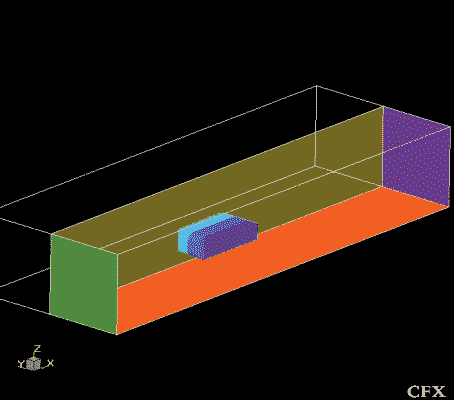
Рис. 1. Вид геометрии и расчетной области

Рис. 2. Вид расчетной сетки
Граничными условиями являются скорость потока на входе (15 м/с), температура потока (15 °С), масштаб и интенсивность турбулентности соответственно 0,1 и 0,05 м. На выходе вниз по течению фиксируется среднее статическое давление, равное атмосферному давлению. На поверхности тела и дороги ставится граничное условие прилипания, соответствующее обращению в нуль скорости потока на этих границах. На остальных поверхностях, являющихся боковыми стенками расчетной области и плоскостью симметрии, ставятся условия скольжения потока, соответствующие обращению в нуль нормальной компоненты скорости на этих границах. Для боковых стенок это условие позволяет отразить реальную картину приближенно, поскольку циркуляция, возникающая при обтекании тела, требует более удаленных границ.
Для проведения расчетов был сгенерирован набор сеток, состоящих из тетраэдрических и призматических элементов. Все сетки были созданы в CFX Build 5.5.1, а пример одной из расчетных сеток представлен на рис. 2. Основное внимание было уделено раскрытию течения около тела и в следе за телом, а также вблизи поверхности дороги. Для проверки масштабируемости затрат и зависимости эффективности параллелизации от объема задачи было построено пять вариантов сеток с почти линейным изменением количества узлов и элементов (табл. 1 и рис. 3 и 4).
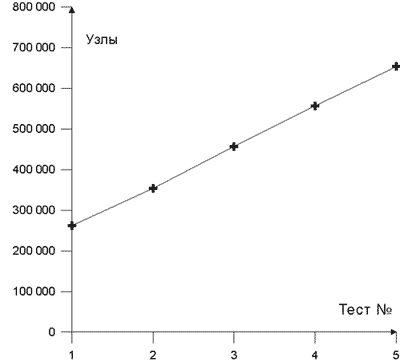
Рис. 3. Количество узлов в расчетных сетках
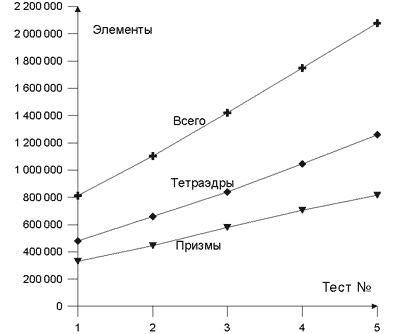
Рис. 4. Количество элементов в расчетных сетках
Загрубление сетки проводилось преимущественно вдали от тела, где нет существенных градиентов в поле течения. За основной показатель качества неструктурированной расчетной сетки бралось отношение сторон элемента (Aspect Ratio). Для самой грубой расчетной сетки данный показатель приблизительно равен 500, что близко к рекомендуемой верхней границе для расчета вязких течений. При этом максимальные значения отношения сторон достигаются для призматических элементов, расположенных на поверхностях, где течение имеет наибольшие градиенты в поперечном к поверхности направлении. Другие показатели качества расчетной сетки также принимались в расчет.
Таблица 1. Параметры расчетных сеток
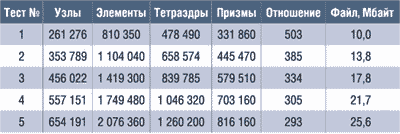
Таблица 2. Полное время расчета Wall Clock Time для различных тестов, с
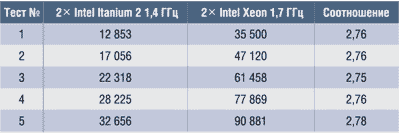
Таблица 3. Процессорное время расчета CPU Time для различных тестов, с
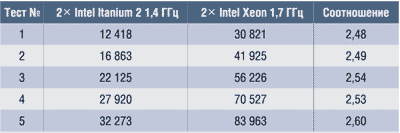
Таблица 4. Объем оперативной памяти для различных тестов (1000 Кб)
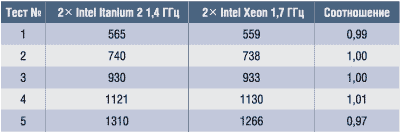
Результаты расчетов
Серии расчетов (рис. 4) проводилась на всех перечисленных вычислительных системах. В качестве основной библиотеки передачи данных между процессорами использовалась библиотека PVM, реализованная в CFX-5. Двойная точность для переменных действительного типа не использовалась, что довольно обычно для многих задач.
В результате решения задачи были получены поля газодинамических переменных в расчетной области. На рис. 5 и 6 показаны визуализированные в цвете картины течения в виде линий тока с окрашиванием по значению модуля скорости и заливки статического давления по твердым поверхностям. Визуализированное численное решение было получено на самой мелкой расчетной сетке (тест № 5) — сначала в режиме счета на установление по времени, потом в режиме нестационарного расчета. Из рис. 5 и 6 видно, что давление в головной части повышается (красный цвет — максимальное значение, синий — минимальное) и что тело возмущает поток во всех направлениях. За телом образуются зона отрывного течения (линии тока синего цвета) и пара вихрей, закрученных в противоположных направлениях. На основе газодинамического анализа такую картину можно считать адекватной.

Рис. 5. Картина линий тока и распределения давления по твердым поверхностям (вид спереди)

Рис. 6. Картина линий тока и распределения давления по твердым поверхностям (вид сзади)
Каждый расчет проводился при 250 шагах интегрирования по времени. Расчеты повторялись четыре раза, время расчета определялось как среднее арифметическое для каждого повторения. Измерялись величины полного времени расчета (Wall Clock Time) и процессорного времени расчета (CPU Time). Отметим, что полное время расчета включает задержку с учетом времени рассылки и сбора данных по процессорам, а также взаимного ожидания процессоров. С помощью утилит top и Windows Task Manager измерялся объем оперативной памяти в ОС Linux и Microsoft Windows 2000. Эти данные, представленные в табл. 2-4, показывают относительную производительность процессоров Intel Itanium 2 1,4 ГГц по сравнению с Intel Xeon 1,7 ГГц при решении задач различного объема. Обе вычислительные системы требуют одинакового объема оперативной памяти при расчете.
Для системы R-Style Marshall EP272r на базе процессора Intel Itanium 2 были проведены замеры процессорного (CPU Time) и полного времени (Wall Clock Time) расчета при работе в одно- и двухпроцессорном режимах. Такие данные позволяют оценить эффективность архитектуры системы с общей памятью и в значительной степени зависят от пропускной способности шины материнской платы. Эти результаты представлены в табл. 5 и показывают, что шина справляется с потоком данных при работе в дуплексном режиме.
Для вычислительного кластера на базе процессоров Intel Xeon 2,8 ГГц были выполнены аналогичные методические вычисления по работе в одно- и двухпроцессорном режимах, результаты которых даны в табл. 6. Результаты показали, что использование общей памяти для двух процессоров, расположенных на одном узле, приводит к конкуренции между процессорами при обращении к оперативной памяти. Вследствие этого при работе в двухпроцессорном режиме не обеспечивается полная загрузка процессоров, о чем свидетельствует ускорение лишь в 1,5-1,6 раза по сравнению с однопроцессорным режимом.
С целью сравнения приведем данные для вычислительного кластера на базе процессоров Intel Xeon 2,8 ГГц при использовании двух двухпроцессорных вычислительных узлов, на каждом из которых было задействовано по одному процессору. Эти данные представлены в табл. 7, из которой видно, что в данном случае ускорение превышает 2. В этом случае каждый процессор монопольно использует всю оперативную память, которая есть на узле, а следовательно, отсутствует конкуренция между процессорами при обращении к оперативной памяти, что обеспечивает наиболее полное использование вычислительных мощностей двухпроцессорной конфигурации. Причем в большинстве случае эффективность двухпроцессорной конфигурации даже выше однопроцессорной, о чем свидетельствуют значения коэффициента ускорения больше 2.
Программный комплекс CFX-5 дает возможность использовать встроенные библиотеки передачи данных между процессорами PVM и MPI. Библиотека MPI рекомендуется для систем с общей памятью, а PVM — как для систем с общей, так и распределенной памятью. С точки зрения сочетания аппаратных и программных средств мы выяснили зависимость показателей быстродействия от параллельной библиотеки. В табл. 8 представлены данные замеров процессорного (CPU Time) и полного времени (Wall Clock Time) расчета при работе в двухпроцессорном режиме системы на базе Intel Itanium 2 для этих двух случаев. Результаты показывают, что для двухпроцессорной системы обе параллельные реализации работают одинаково быстро.
Таблица 5. Процессорное (CPU Time) и полное (Wall Clock Time) время расчета для режимов 1ЅIntel Itanium 2 и 2ЅIntel Itanium 2 Local PVM, с

Таблица 6. Процессорное (CPU Time) и полное (Wall Clock Time) время расчета для режимов 1Ѕ Intel Xeon и 2Ѕ Intel Xeon Local PVM, с

Таблица 7. Процессорное (CPU Time) и полное (Wall Clock Time) время расчета для режимов 1Ѕ Intel Xeon и 2Ѕ Intel Xeon Distributed PVM, с

Таблица 8. Процессорное (CPU Time) и полное (Wall Clock Time) время расчета для режима 2Ѕ Intel Itanium 2 при использовании
библиотек PVM и MPI, с

Инженерная задача
Характерной для инжинирингового центра ОАО «Криогенмаш» задачей является расчет течения и определение характеристик промышленного центробежного компрессора. Объем рассматриваемой задачи составляет 1 898 600 узлов (1 832 076 элементов-гексаэдров), а суммарная расчетная область состоит из четырех областей. Этап расчета включает 500 шагов по времени; для определения характеристик проводилось несколько последовательных расчетов. По итогам обработки данных полное время расчета Wall Clock Time составило 136 397 с, а процессорное время расчета CPU Time составило 136 008 с для системы на базе 2xIntel Itanium 2 1,4 ГГц. Такие же расчеты были проведены в системе на базе 4x2x Intel Xeon 2,8 ГГц, где полное время расчета Wall Clock Time было 64 490 с, а процессорное время расчета CPU Time — 50 170 с. На основе этих данных можно сказать, что производительность, вычисленная по затратам процессорного времени с учетом количества процессоров, в первом случае почти в 1,5 раза выше.
Анализ результатов
При рассмотрении результатов тестирования за основные показатели мы приняли масштабируемость затрат по процессорному времени расчета (CPU Time) в зависимости от объема задачи, эффективность параллельного расчета на системе с общей памятью и производительность.
Наглядное представление о масштабируемости затрат времени процессора на расчет задач различного объема в параллельном режиме (см. табл. 3, 5 и 6) для систем на базе процессоров Intel Itanium 2 и Intel Xeon можно получить из рис. 7.
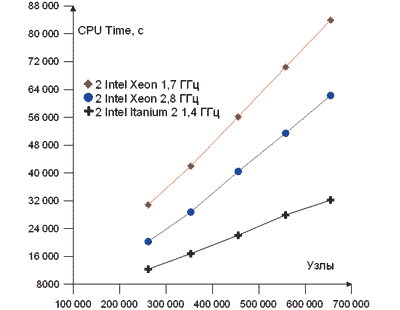
Рис. 7. Зависимость процессорного времени расчета CPU Time (с) от объема задачи
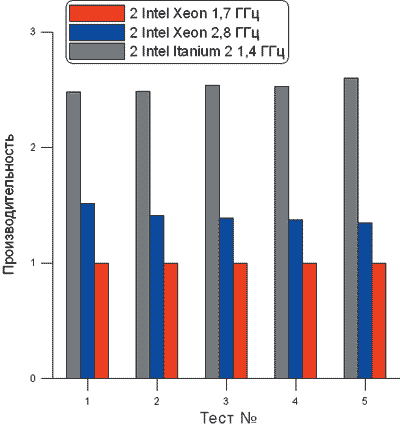
Рис. 8. Производительность различных вычислительных систем
Чтобы привести данные о производительности всех систем (обратно пропорциональной времени процессора CPU Time) к единому виду (см. табл. 3 и 6), следует отнести их к данным для системы на базе процессоров Intel Xeon 1,7 ГГц для каждого теста. На рис. 8 в виде диаграммы показаны данные о производительности различных систем.
На основе имеющихся данных в табл. 3, 5 и 6 в описании инженерной задачи и рис. 7 и 8 можно определенно сказать, что аппаратно-программное решение на базе процессоров Intel Itanium 2 демонстрирует более высокую производительность по сравнению с решениями на базе процессоров Intel Xeon. В среднем по показателю CPU Time соотношение производительности составляет 2,53 при сопоставимой частоте процессора (см. табл. 3), а по показателю Wall Clock Time это отношение еще больше — 2,76 (см. табл. 2). Можно отметить, что с ростом объема задачи отношение производительности по CPU Time немного возрастает (см. табл. 3). Это можно связать с тем, что при увеличении объема вычислений усиливается роль архитектуры системы. При этом объем оперативной памяти, занимаемой задачей, практически одинаков для обеих платформ (см. табл. 4).
Для систем с общей памятью важно сопоставить ускорение расчета при сравнении одно- и двухпроцессорного режимов. Это было сделано для R-Style Marshall EP272r и для системы на базе Intel Xeon 2,8 ГГц (см. табл. 5 и 6). Результаты тестирования показали высокую эффективность первой системы (среднее ускорение — 1,96 по CPU Time и 1,92 по Wall Clock Time), причем ускорение росло по мере роста объема задачи, достигая величин 2,03 и 2,0 соответственно. Для системы на базе процессоров Intel Xeon 2,8 ГГц показатели ускорения скромнее — 1,59 и 1,55 соответственно при тенденции снижения вследствие роста объема задачи. «Суперлинейное» ускорение в первом случае можно объяснить особенностями архитектуры и объемом кэш-памяти рассматриваемых процессоров — 4 Мбайт L3 у Intel Itanium 2 и 512 Кбайт L2 у Intel Xeon.
Эти результаты интересны с точки зрения данных о показателях ускорения, представленных компанией Intel на базе сведений, которые были получены от различных компаний, производящих программное обеспечение (http://www.intel.com/business/bss/swapps/hpc/evalofplatformperf.pdf). Комплекс CFX-5, информация о котором не отражена в указанном источнике, оказался в весьма выигрышном положении в плане эффективности использования архитектуры системы и организации параллельных вычислений. На рис. 7 и 8 показано принципиальное преимущество систем на базе Intel Itanium 2 по сравнению с 32-разрядной вычислительной архитектурой.
Показатели ускорения для распределенных вычислений в конфигурации, когда на многопроцессорном узле задействован один процессор (см. табл. 7), тоже являются познавательными, но они не вполне показательны. Это связано с тем, что вычислительная нагрузка на процессор в такой конфигурации может быть ослаблена из-за использования других процессоров на узле.
Для инженерной задачи ОАО «Криогенмаш» разброс данных по затратам оказался достаточно большим, что может быть обусловлено неравномерным объемом вычислений по ходу расчета. Тем не менее сравнительные показатели производительности позволяют сделать вывод о преимуществе систем на базе процессоров Intel Itanium 2.
Результаты тестирования позволяют сделать вывод о высокой производительности комплексов на базе процессоров Intel Itanium 2 (R-Style Marshall EP272r) и охарактеризовать такие решения, как очередной шаг в технологии параллельных вычислений. Можно отметить эффективную организацию параллельных вычислений в программном комплексе CFX-5 и рекомендовать к применению рассматриваемое аппаратно-программное решение на промышленных предприятиях и в учебных заведениях.
Иван Воронич Ассистент кафедры компьютерного моделирования факультета аэромеханики и летательной техники МФТИ. Леонтий Ивчик Инженер-конструктор инжинирингового центра ОАО «Криогенмаш». Владимир Коньшин Менеджер отдела вычислительной гидродинамики компании «ТЕСИС», канд. физ.-мат. наук. Юрий Мигаль Менеджер по работе с корпоративными заказчиками компании R-Style Computers. Андрей Помысов Ведущий инженер-конструктор инжинирингового центра ОАО «Криогенмаш». Владимир Ткаченко Ассистент кафедры компьютерного моделирования факультета аэромеханики и летательной техники МФТИ. |
«САПР и графика» 6'2005

