
Ускорение инженерных расчетов в ANSYS Mechanical при использовании технологии NVIDIA Maximus
Ускорение расчетов с помощью GPU
Благодаря развитию систем инженерного анализа (CAE) сегодня инженеры во многих отраслях промышленности всё чаще проводят виртуальные испытания разрабатываемых изделий. Специалисты стремятся максимально приблизить виртуальные эксперименты к реальности и получить наиболее адекватные результаты путем учета всех возможных технических деталей в расчетной модели. Растут расчетные возможности CAEсистем, в результате увеличиваются размерности задач, и возникает необходимость в расширении вычислительной базы расчетных подразделений. В настоящее время в области высокопроизводительных вычислений (High Performance Computing, HPC) всё более остро встает проблема нехватки вычислительных ресурсов.
Традиционный подход к решению задач, состоящий в использовании центральных процессоров (CPU) и увеличении их производительности, уже не может справиться с необходимостью постоянного наращивания вычислительных мощностей. Технологический предел производительности для CPU оставляет единственную возможность масштабирования таких вычислительных систем — добавление десятков, сотен и даже тысяч отдельных вычислительных серверов и формирование вычислительного кластера. Этот подход требует серьезных финансовых затрат, и энергопотребление такой системы весьма существенно. Иной подход, зародившийся совсем недавно, вводит сферу HPC в эру гибридной модели вычислений, где на помощь CPU приходит графический процессор (GPU).
Предложение применять графический процессор в качестве компаньона при расчете сложных инженерных задач стало глотком свежего воздуха в сложившейся обстановке технологического тупика в производительности CPU. Возможность использования GPU в вычислениях позволила разделять сложные вычислительные задачи на тысячи небольших и решать их параллельно на ядрах графического процессора. Данная технология дала инженерам и исследователям возможность получать результаты численного анализа в разы быстрее. Кроме того, системы, использующие GPU, оказались более экономичными с точки зрения энергопотребления, чем традиционные кластерные системы только на базе CPU.
Основное различие процессоров CPU и GPU состоит в их архитектуре. Будучи по природе параллельным процессором, GPU значительно превосходит CPU в обработке большого объема однотипных данных. А CPU, являясь последовательным процессором, изначально не разрабатывался для подобного класса задач и предназначался именно для последовательных операций, таких как работа с операционной системой и организация потоков данных. Проведение вычислений с применением GPU стало возможным благодаря созданию специфической архитектуры графических процессоров CUDA от NVIDIA, позволяющей задействовать сотни вычислительных ядер, работающих параллельно.
Передовая сегодня гибридная модель вычислений состоит в совместном использовании CPU и GPU, при этом последовательная часть кода приложения выполняется на CPU, а вся ресурсоемкая часть обработки больших объемов данных — на GPU.
Технология NVIDIA Maximus
Технология CUDA для организации параллельных вычислений с использованием GPU была представлена в феврале 2007 года компанией NVIDIA. Однако прогресс не стоит на месте, и сегодня NVIDIA предлагает технологию NVIDIA Maximus, позволяющую задействовать весь потенциал процессоров CUDA на базе нескольких карт NVIDIA, работающих параллельно. Рабочие станции на основе технологии NVIDIA Maximus объединяют возможности визуализации и интерактивного проектирования графических процессоров NVIDIA Quadro с высокопроизводительной вычислительной мощностью графических процессоров NVIDIA Tesla на одной рабочей станции. Сопроцессоры Tesla при этом автоматически берут на себя выполнение ресурсоемких частей кода приложений, например вычислений при численном моделировании или выполнение фотореалистичного рендеринга изображений. Это автоматически снимает нагрузку с CPU, позволяя ему работать в привычном режиме: вводвывод данных, запуск операционной системы и обеспечение многозадачности. При этом графические процессоры Quadro или Tesla производят операции, требующие высокой производительности. Конструкторы и инженеры получили возможность одновременно осуществлять проектирование в CADсистемах и проводить численный анализ в CAEпакетах на той же рабочей станции.

Директор по стратегическому партнерству компании ANSYS, Inc., являющейся лидером рынка CAEсистем, Барбара Хатчингс (Barbara Hutchings) отмечает: «GPUвычисления способны значительно ускорить расчеты в программных продуктах ANSYS на рабочих станциях, а в некоторых случаях даже удвоить количество расчетов, что помогает нашим клиентам более широко использовать технологические возможности. С тех пор как платформа NVIDIA Maximus стала широко доступна, предприятиям легче использовать программные продукты ANSYS в офисе для интерактивных и вычислительных задач».
Расчетные возможности продуктов ANSYS включают поддержку вычислений с участием GPU начиная с 13й версии программного обеспечения ANSYS, появившейся в ноябре 2011 года. В бетаверсии ANSYS 14.5, готовящейся к выходу на момент написания статьи, разработчики заявили о возможности проведения расчетов на базе нескольких GPU. Являясь официальным партнером ANSYS, Inc. в России, компания ЗАО «КАДФЕМ СиАйЭс» протестировала работу технологии NVIDIA Maximus, выполнив серию расчетов в новой версии ANSYS Mechanical.
Maximus — это универсальная технология, предполагающая возможность балансирования нагрузки между графическими процессорами разных типов. Несмотря на то что основное назначение Maximus — разделение необходимых ресурсов для визуализации и CUDAвычислений на различные процессоры (например, визуализация выполняется на Quadro, вычисления — на Tesla), в ANSYS Mechanical изза большой размерности задач все подключенные GPU использовались только для вычислений. Оценка еще одного преимущества технологии Maximus — возможности одновременной работы с задачами разных типов (визуализации сложных с графической точки зрения моделей и реализации ресурсоемких вычислений) — станет предметом наших дальнейших исследований. В рамках этого тестирования оценивалась работа решателей ANSYS Mechanical с участием нескольких GPU.
Тестовый стенд
Стенд для тестирования производительности расчетов с использованием технологии NVIDIA Maximus предоставлен инженерам ЗАО «КАДФЕМ СиАйЭс» партнером NVIDIA в России, разработчиком и поставщиком решений, продуктов и услуг в области информационных технологий — компанией ARBYTE. Характеристики тестового стенда приведены в табл. 1.
В табл. 2 приведены характеристики использованных графических процессоров.

Таблица 1. Характеристики тестового стенда
Параметры |
Значения |
Модель рабочей станции |
ARBYTE CADStation WS 479 |
CPU |
Intel Core i7 3960X, 3,30 ГГц |
RAM |
64 Гбайт DDR3 1600 МГц (PC312800) |
GPU #1 |
NVIDIA Quadro 6000 |
GPU #2 |
NVIDIA Tesla C2075 |
GPU #3 |
NVIDIA Tesla C2075 |
Твердотельный накопитель (SDD) |
60 Гбайт |
Жесткий диск (HDD) |
300 Гбайт, 10 000 об./мин |
Операционная система |
Microsoft Windows 7 Профессиональная 64 bit, версия 6.1.7601 Service Pack 1 |
Программное обеспечение ANSYS, Inc. |
ANSYS 14.5 |
Модель процессора Параметры \ |
NVIDIA Quadro 6000 |
NVIDIA Tesla C2075 |
Число ядер CUDA |
448 |
448 |
Объем памяти |
6 Гбайт GDDR5 |
6 Гбайт GDDR5 |
Интерфейс памяти |
384 бит |
384 бит |
Пропускная способность памяти |
144 Гбайт/с |
144 Гбайт/с |
Частота ядер |
1,15 ГГц |
1,15 ГГц |
Одинарная точность |
1030,4 Гфлоп |
1030,4 Гфлоп |
Двойная точность |
515,2 Гфлоп |
515,2 Гфлоп |
Энергопотребление |
204 Вт |
225 Вт |
Ускорение расчетов в ANSYS Mechanical 14.5 с помощью GPU
Технология использования GPU при проведении расчетов уже дает ощутимый прирост производительности. Опираясь на результаты тестирования решателей предыдущего поколения, проведенного инженерами ANSYS, Inc. и ЗАО «КАДФЕМ СиАйЭс», можно сделать вывод о приросте производительности в среднем на 1030% и до 250% при решении определенных задач. Недостатком поддержки GPU в решателях ANSYS Mechanical всех предыдущих версий была необходимость того, чтобы задача целиком помещалась в память GPU.
Поэтому в первую очередь тестирование ускорения проводилось на базе одиночного GPU для определения производительности системы в целом. Для тестирования производительности рабочей станции с одним GPU NVIDIA Quadro 6000 в ANSYS Mechanical были выбраны несколько задач различной размерности: стандартные тесты производительности из набора ANSYS SP1 BENCH110 Benchmark Suite, в которых присутствуют линейные/нелинейные, стационарные/нестационарные задачи теории упругости, теории колебаний, а также отдельные задачи теории упругости и колебаний. Задачи представлены на рис. 1, а результаты тестирования приведены на рис. 2.
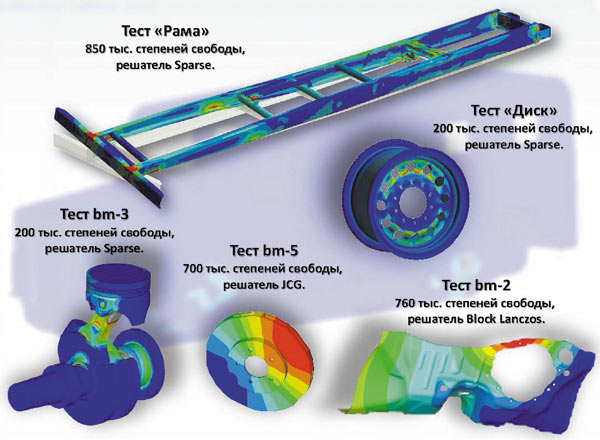
Рис. 1. Варианты тестовых оценочных задач
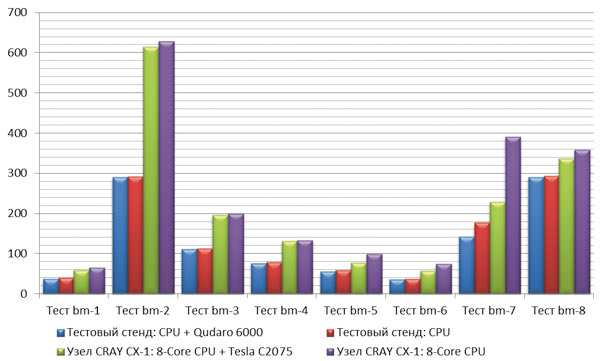
Рис. 2. Время расчета задач (с) при тестировании GPU-ускорения ANSYS Mechanical 14.5 Preview 2
В целом по результатам этих тестов получен ожидаемый результат — производительность системы с применением GPUускорения расчетов увеличивается на 1030%. Однако цель тестирования состояла в оценке работы решателей ANSYS Mechanical с технологией NVIDIA Maximus.
Подготовка оборудования
На этапе подготовки в первую очередь была настроена работа NVIDIA Maximus.
С целью обеспечения максимально быстрого обмена данными по шине PCIe графические процессоры были выставлены в следующей конфигурации:
- GPU #1 (NVIDIA Quadro 6000) — в слот PCIe x16;
- GPU #2 (NVIDIA Tesla C2075) — в слот PCIe x16;
- GPU #3 (NVIDIA Tesla C2075) — в слот PCIe x8.
Посредством Maximus Configuration Utility всем трем картам была определена возможность производить CUDAвычисления, а NVIDIA Quadro использовалась и для вычислений, и для вывода графики.
Основное тестирование работы решателей ANSYS Mechanical 14.5 с NVIDIA Maximus
Тестирование возможности ускорения вычислений проводилось на трех наиболее часто используемых на практике решателях ANSYS Mechanical 14.5: Sparse, PCG и Block Lanczos.
Решатель Sparse (с разреженной матрицей) применяется для наиболее быстрого поиска решения в нелинейных расчетах, а также в линейных расчетах, где итерационные решатели медленно достигают сходимости (особенно при низком качестве конечноэлементной модели). Решатель PCG (методом сопряженных градиентов с предобусловленной матрицей) имеет меньший объем операций вводавывода данных относительно решателя Sparse и лучше подходит для задач большой размерности с Solidэлементами и густой сеткой. Это наиболее надежный итерационный решатель ANSYS Mechanical. Решатель Block Lanczos (по блочному методу Ланцоша) используется в динамических расчетах, проводимых в ANSYS Mechanical, для поиска собственных частот и форм колебаний конструкции.
Все задачи решались в режиме INCORE, который определяет размещение всех необходимых решателю данных в оперативную память и использует жесткий диск исключительно для чтения исходных данных и записи окончательных и промежуточных результатов. Этот режим применения памяти отличается наибольшей производительностью. Запуск тестовых задач осуществлялся из командной строки.
Поддержка нескольких GPU решателями ANSYS Mechanical
Для корректной работы решателей ANSYS Mechanical с несколькими GPU требуется соблюдение следующих условий:
- на машине должен быть установлен один или несколько графических процессоров NVIDIA Tesla (рекомендованы карты 20й серии) или/и один NVIDIA Quadro. Если установлены и Quadro и Tesla, то решатель ANSYS Mechanical выберет в качестве основного GPU — Tesla;
- на операционных системах семейств Windows x64 и Linux x64 должны быть установлены драйверы актуальной версии. Для операционных систем Windows рекомендуется использование режима работы драйвера TCC (Tesla Compute Cluster);
- согласно лицензионной политике ANSYS, Inc. для применения GPU в расчетах необходимо наличие лицензий ANSYS HPC Pack, используемых для организации доступа к параллельным вычислениям на CPU;
- поддержка нескольких GPU в расчетах возможна только в режиме распределенных вычислений (Distributed ANSYS) и только в том случае, когда число запущенных процессов ANSYS Mechanical превышает количество применяемых GPU.
Дополнительные опции
В операционной системе можно определить следующие переменные среды:
- ANSGPU_PRINTDEVICES = 1, в этом случае решатель ANSYS Mechanical при каждом запуске будет выводить в рабочую директорию файл AnsGPUdevices.lst, где будут перечислены все GPU с поддержкой CUDA, доступные в системе в том приоритетном порядке, в котором их будет использовать решатель;
- ANSGPU_DEVICE = N, где N —– идентификатор (ID) того GPU из списка AnsGPUdevices.lst, который решатель должен использовать. Эта переменная позволяет избежать одновременного применения одного GPU двумя и более пользователями многопользовательской среды. Следует особо отметить, что определение этой переменной среды автоматически отключает возможность использования нескольких GPU в одном расчете.
Также реализована возможность отключения коррекции ошибок памяти (ECC), которая позволяет применять больший объем памяти GPU. Однако для обеспечения точности результатов расчетов этой возможностью пользоваться не рекомендуется.
Тестирование решателя Sparse
Для проведения тестов решателя Sparse были подготовлены однотипные статические задачи теории упругости с десятью подшагами нагружения, занимающие от 4 до 50 Гбайт оперативной памяти (от 220 тыс. до 1,370 млн степеней свободы). Результаты тестирования показаны на рис. 3.
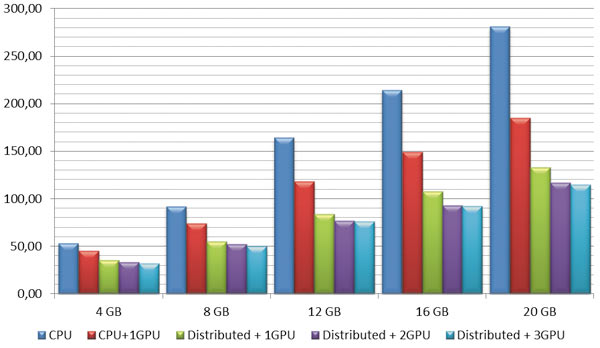
Рис. 3. Время расчета задач решателем Sparse, с
Интересная особенность проявляется при дальнейшем росте размерности задачи. Поскольку режим распределения вычисления на несколько расчетных ядер сопряжен с дополнительными затратами вычислительной мощности на декомпозицию задачи и дальнейшее объединение данных с нескольких ядер в один результат, то для некоторого класса задач решение в режиме SMP (Shared Memory Parallel) оказывается значительно быстрее, чем в режиме распределенных вычислений DMP (Distributed Memory Parallel). В случае применения ускорения GPU наблюдается аналогичная ситуация (рис. 4). Задача с размерностью 50 Гбайт в режиме DMP заняла в памяти суммарно 67 Гбайт, поэтому решение в режиме INCORE стало невозможным.
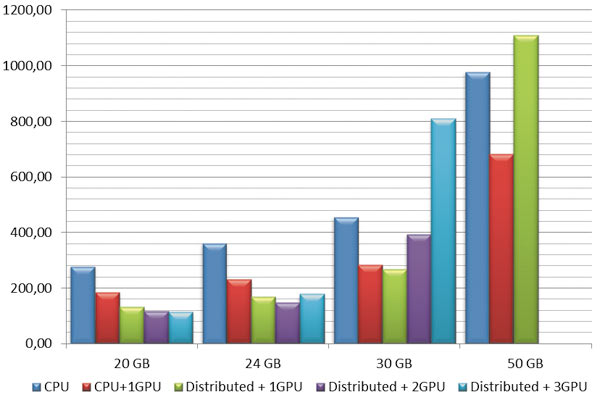
Рис. 4. Время расчета задач большой размерности решателем Sparse, с
Загрузку GPU в процессе расчета можно наблюдать с помощью утилиты NVIDIA System Management Interface program (NVIDIAsmi.exe) из комплекта драйверов NVIDIA. С ее помощью можно записать в logфайл таблицу загрузки графических процессоров (рис. 5) с периодичностью примерно 5 с.
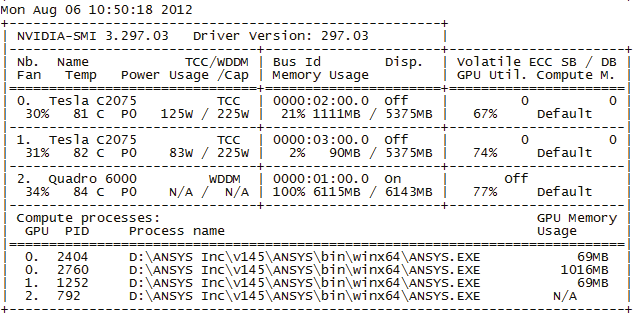
Рис. 5. Таблица контроля загрузки GPU в log-файле NVIDIA System Management Interface program
Анализируя загрузку GPU по logфайлам, мы заметили, что для хранения информации в основном использовалась GPU Tesla, а в вычислениях непосредственно участвовало столько GPU, сколько указано в параметрах запуска. При этом GPU применялись исключительно в процессе решения задачи. На этапе подготовки задачи и формирования матриц работал только CPU, а части сформированных матриц сразу передавались в память GPU в момент начала решения.
Тестирование решателя PCG
Для тестирования решателя PCG был подготовлен ряд прочностных задач с контактным взаимодействием, занимающих объем оперативной памяти от 4 до 50 Гбайт (от 190 тыс. до 1,315 млн степеней свободы). Ощутимого прироста производительности за счет использования GPU, как для решателя SPARSE, в данном случае не наблюдается. Гистограмма времени проведения расчетов показана на рис. 6.
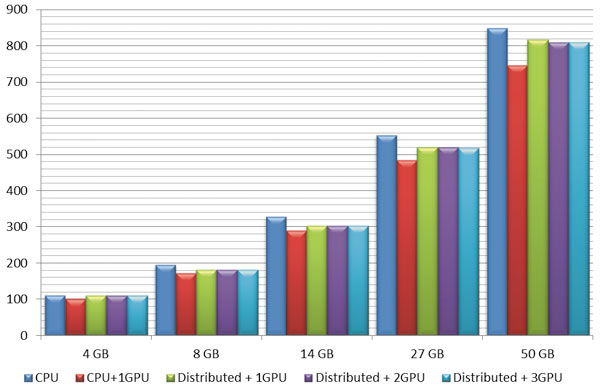
Рис. 6. Время расчета задач решателем PCG, с
Тестирование решателя Block Lanczos
Для тестирования производительности решателя Block Lanczos были подготовлены задачи поиска 20 собственных частот конструкции, занимающие от 4 до 44 Гбайт оперативной памяти. Для решателя Block Lanczos ощутимого прироста производительности за счет использования GPU также не наблюдалось. Гистограмма времени проведения расчетов показана на рис. 7.
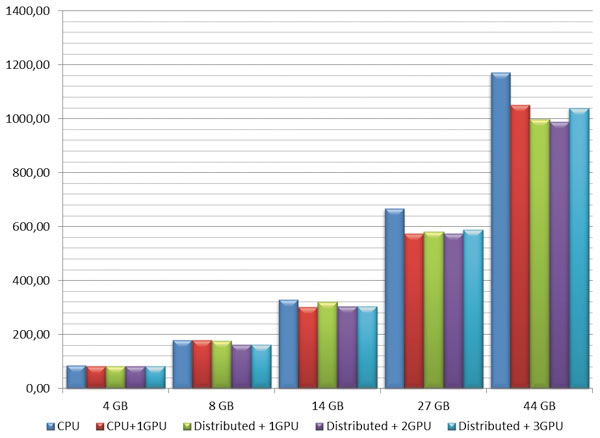
Рис. 7. Время расчета задач решателем Block Lanczos, с
Выводы
В ANSYS Mechanical 14.5, по сравнению с предыдущими версиями, реализованы и доработаны следующие функциональные возможности, связанные с использованием GPU при расчетах:
- предоставлена возможность применения нескольких GPU при расчетах в режиме распределенных вычислений на локальной расчетной станции. Загрузка GPU во время тестирования была проверена с помощью специализированной утилиты NVIDIA;
- устранено ограничение размерности задач, решаемых с участием GPU, связанное с нехваткой графической памяти для размещения задачи. Во время тестирования решались задачи размерностью до 50 Гбайт, что существенно превышает суммарный объем видеопамяти предоставленных графических карт.
Подводя итог, можно утверждать, что решатели ANSYS Mechanical постоянно модифицируются: увеличивается эффективность производимых ими расчетов, снижается нагрузка на файловую подсистему. Появившаяся в версии ANSYS Mechanical 14.5 поддержка ускорения расчетов с применением нескольких GPU по технологии NVIDIA Maximus позволит инженерам значительно сократить время расчетов существующих классов задач и повысить размерность вновь создаваемых конечноэлементных моделей.
По результатам тестирования видно, что использование нескольких графических процессоров дает существенное ускорение расчета задач теории упругости методом Sparse в режиме распределенных вычислений. Сравнение полного времени расчета тестовых задач, включающего подготовку конечноэлементных моделей и формирование файлов результатов, показало эффективный прирост производительности решателя относительно расчетов без использования GPU в 2,5 раза. При этом чем больше размерность задачи, тем ощутимее будет вклад от применения нескольких GPU.
Для решателей PCG и Block Lanczos прирост относительной производительности наблюдается, но его величина ниже, чем при решении задач методом Sparse. Для решателя PCG с ростом размерности задачи становится более очевидным сокращение времени расчета с использованием одного, двух и трех GPU. Однако затраты времени на декомпозицию задачи оказываются существенными, поэтому максимальная производительность данного решателя проявляется в режиме SMP с ускорением с помощью одного GPU. Максимальный прирост относительной производительности системы с несколькими GPU составил 9%, а в режиме SMP — 14,5%. Для решателя Block Lanczos затраты времени на декомпозицию задачи аналогичным образом возрастают с увеличением ее размерности. Поэтому начиная с задач определенной размерности время расчетов задач с ростом числа используемых GPU возрастает. И чем больше применяется GPU, тем больше времени затрачивается на декомпозицию и сборку задачи. Максимальный прирост относительной производительности решателя Block Lanczos с помощью нескольких GPU составил приблизительно 18,5%, а в режиме SMP — 16,5%.
В целом использование вычислительных средств с подобными конфигурациями оправдывает ожидания и экономические затраты на их приобретение. Рабочие станции данного класса позволят в короткие сроки получить точные результаты расчетов, сокращая процесс разработки новой продукции.
Специалисты ЗАО «КАДФЕМ СиАйЭс» выражают благодарность руководству и техническому персоналу ЗАО «АРБАЙТ КОМПЬЮТЕРЗ» за предоставленное оборудование и техническую поддержку в процессе тестирования.

